Evaluation of Usuba-generated ciphers on Intel CPUs
Usuba vs Hand-tuned
In the following, we benchmark Usuba-generated implementations against hand-written C or assembly implementations. When possible, we benchmark only the cryptographic primitive, ignoring key schedule, transposition, and mode of operation. To do so, we picked open-source reference implementations that were self-identified as optimized for high-end CPUs. The ciphers we considered are DES, AES, Chacha20, Serpent, Rectangle, Gimli, Ascon, Ace and Clyde. We also evaluate the performances of Usuba on Pyjamask, Xoodoo and Gift, although we did not find speed-optimized reference implementations.
Several reference implementations (AES, Chacha20, Serpent) are written in assembly, without a clear separation between the primitive and the mode of operations, and only provide an API to encrypt bytes in CTR mode. To compare ourselves with those implementations, we implemented the same mode of operation in C, following their code as closely as possible. This puts us at a slight disadvantage, because assembly implementations tend to fuse the cryptographic runtime (i.e. mode and transposition) into the primitive, thus enabling further optimizations. We used the Supercop framework to benchmark these implementations (since the reference were already designed to interface with it), and the cost we report below include key schedule, transposition (when a transposition is needed) and management of the counter (since they are ran in CTR mode).
For implementations that were not designed to interface with Supercop
(DES, Rectangle, Gimli, Ascon, Ace, Clyde), we wrote our own
benchmarking code, which merely consists of a loop running the cipher
and timed using rdtscp. The cost of transposing data is omitted from
our results, since transposition is done outside of Usuba. Note that
the transposition costs vary depending on the cipher, the slicing mode
and the architecture: transposing bitslice DES’s inputs and outputs
costs about 3 cycles per bytes (on general purpose registers); while
transposing vsliced Serpent’s inputs and outputs costs about 0.38
cycles/bytes on SSE and AVX, and 0.19 on AVX2.
We have conducted our benchmarks on a Intel(R) Core(TM) i5-6500 CPU @ 3.20GHz machine running Ubuntu 16.04.5 LTS (Xenial Xerus) with Clang 7.0.0, GCC 8.4.0 and ICC 19.1.0. Our experiments showed that no C compiler is strictly better than the others. ICC is for instance better to compile our Chacha20 implementation on AVX2, while Clang is better to compile our Serpent implementation on AVX. We thus compiled both the reference implementations and ours with Clang, ICC and GCC, and selected the best performing ones.
In the following table, we report the benchmarks of our Usuba implementations of 9 ciphers against the most efficient publicly available implementations. In all cases we instructed Usubac to generate code using the same SIMD extensions as the reference. We also provide the SLOC (source lines of code) count of the cipher primitive (i.e. excluding key schedule and counter management) for every implementation. Usuba programs are almost always shorter than the reference ones, as well as more portable: for each cipher, a single Usuba code is used to generate every specialized SIMD code.
| Mode | Cipher | Instr. set |
Code size (SLOC) |
Throughput (cycles/byte) |
Speedup | ||
|---|---|---|---|---|---|---|---|
| Ref. | Usuba | Ref. | Usuba | ||||
| bitslicing | DES | x86-64 | 1053 | 655 | 11.31 | 10.63 | +6.01% |
| 16-hslicing | AES | SSSE3 | 272 | 218 | 5.49 | 5.93 | -3.49% |
| 16-hslicing | AES | AVX | 339 | 218 | 5.53 | 5.81 | -5.06% |
| 32-vslicing | Chacha20 | AVX2 | 20 | 24 | 1.00 | 0.99 | +1% |
| 32-vslicing | Chacha20 | AVX | 134 | 24 | 2.00 | 1.98 | +1% |
| 32-vslicing | Chacha20 | SSSE3 | 134 | 24 | 2.05 | 2.08 | -1.46% |
| 32-vslicing | Chacha20 | x86-64 | 26 | 24 | 5.58 | 5.20 | +6.81% |
| 32-vslicing | Serpent | AVX2 | 300 | 214 | 4.17 | 4.25 | -1.92% |
| 32-vslicing | Serpent | AVX | 300 | 214 | 8.15 | 8.12 | +0.37% |
| 32-vslicing | Serpent | SSE2 | 300 | 214 | 8.61 | 8.62 | -0.12% |
| 32-vslicing | Serpent | x86-64 | 300 | 214 | 30.95 | 22.37 | +27.72% |
| 16-vslicing | Rectangle | AVX2 | 115 | 31 | 2.28 | 1.79 | +21.49% |
| 16-vslicing | Rectangle | AVX | 115 | 31 | 4.55 | 3.58 | +21.32% |
| 16-vslicing | Rectangle | SSE4.2 | 115 | 31 | 5.80 | 3.71 | +36.03% |
| 16-vslicing | Rectangle | x86-64 | 115 | 31 | 26.49 | 21.77 | +17.82% |
| 32-vslicing | Gimli | SSE4.2 | 70 | 52 | 3.68 | 3.11 | +15.49% |
| 32-vslicing | Gimli | AVX2 | 117 | 52 | 1.50 | 1.57 | -4.67% |
| 64-vslicing | Ascon | x86-64 | 68 | 55 | 4.96 | 3.73 | +24.80% |
| 32-vslicing | Ace | SSE4.2 | 110 | 43 | 18.06 | 10.35 | +42.69% |
| 32-vslicing | Ace | AVX2 | 132 | 43 | 9.24 | 4.55 | +50.86% |
| 64-vslicing | Clyde | x86-64 | 75 | 71 | 15.22 | 10.79 | +29.11% |
Our first benchmark is DES [1]. Needless to say, DES is not secure and should not be used in practice. However, the simplicity and longevity of DES makes for an interesting benchmark: bitslicing was born out of the desire to provide fast software implementations of DES. There exists several publicly-available, optimized C implementations in bitsliced mode for 64-bit general-purpose registers. The performances of the reference implementation, and even more, of Usuba’s implementation are reliant on the C compiler’s ability to find an efficient register allocation: Clang produces a code that is 11.5% faster than gcc for the reference implementation, and 12% faster than icc for the Usuba implementation.
Using the standard Usuba compiler produces a DES implementation which is 6% slower than the reference. Inspecting the assembly reveals that the Usuba-generated code compiled with Clang contains 25% more spilling than the reference implementation. In an effort to reduce the spilling, we wrote an algorithm that aims at detecting long-lived values, and explicitly spill them (by storing them in an array rather than using variables for them) in order to free up registers for other shorter lived values. In practice, the impact of this algorithm is very erratic, improving some ciphers, but considerably degrading others, and is hard to justify since in the end, it relies on “being lucky” when choosing which values to spill, which is why we did not discuss it in the Backend post. Still, this algorithm is able to reduce register pressure in our DES implementation, allowing it to perform better than the hand-tuned reference implementation. Still, more work remains to be done on the scheduling of bitsliced codes.
Our second benchmark is AES [2], whose fastest handtuned SSSE3 and AVX implementations are hsliced. The two reference implementations are given in hand-tuned assembly. On AVX, one can take advantage of 3-operand, non-destructive instructions, which significantly reduces register pressure. Thanks to Usubac, we have compiled our (single) implementation of AES to both targets, our AVX implementation taking full advantage of the extended instruction set thanks to the C compiler. Our generated code lags behind hand-tuned implementations for two reasons. First, the latter fuse the implementation of the counter-mode (CTR) run-time into the cipher itself. In particular, they locally violate x86 calling conventions so that they can return multiple values within registers instead of returning a pointer to a structure. Second, the register pressure is high because the S-box requires more temporaries than there are available registers. While hand-written implementations were written in a way to minimize spilling, we rely on the C compiler to allocate registers, and in the case of AES, they do not manage to find the optimal allocation.
Chacha20 [3] has been designed to be efficiently implementable in
software, with an eye toward SIMD. The fastest implementations to date
are vsliced, although some very efficient implementations use a mix of
vslicing and hslicing (discussed in the Future work post). As shown in the
Scheduling post, Chacha20 is composed of four calls to a quarter round (QR)
function. This function is bound by data dependencies, and the key to
efficiently implement Chacha20 is to interleave the execution of these
four functions in order to remove any data hazards. Usubac’s scheduler
is able to do so automatically, thus allowing us to perform on-par
with hand-tuned implementations.
Serpent [4] was another contender to the AES competition, and was designed with bitslicing in mind. It can be implemented with less than 8 64-bit registers. Its fastest implementation is written in assembly, exploiting the AVX2 instruction set. The reference AVX2, AVX and SSE implementations manually interleave 2 parallel instances of the cipher. Usubac’s auto-tuner however is able to detect that on AVX2 and AVX, interleaving 3 implementations is slightly more efficient, thus yielding performances similar to the reference implementations. When interleaving 2 implementations, Usubac is a couple of percents slower than hand-tuned implementations. On general purpose registers, the reference implementation is not interleaved, while Usuba’s implementation is, hence the 27% speedup.
Rectangle [5] is a lightweight cipher, designed for relatively fast execution on micro-controllers. It only consumes a handful of registers. We found no high-performance implementations online. However, the authors were kind enough to send us their SIMD-optimized implementations. These implementations are manually vsliced in C++ and fails to take advantage of interleaving: as a result, our straightforward Usuba implementation easily outperforms the reference one.
Gimli [6] is a lightweight permutation, candidate to the NIST Lightweight Cryptography Competition (LWC). The reference implementations rely on a hybrid mslicing technique, mixing aspects of vslicing and hslicing (discussed in the Future work post). This hybrid mslicing requires less registers than pure vslicing, at the expense of additional shuffles. The AVX2 implementation takes advantage of the reduced register pressure to enable interleaving, which would not be efficient in purely vsliced implementation. However, the authors chose not to interleave their SSE implementations, allowing Usuba to be 15% faster. Note that another benefit of the hybrid mslicing used in the reference implementations is that they require less independent inputs to be efficient. This would make the reference implementations faster if less than 4 (on SSE) or 8 (on AVX2) blocks need to be encrypted.
Ascon [7] is another candidate of the LWC. The authors provided an optimized implementation, written in a low-level C: loops have been manually unrolled and functions manually inlined. In addition to unrolling and inlining nodes, Usubac interleaves Ascon twice, thus resulting in a 25% speedup over this reference implementation. When disabling interleaving and scheduling, the Usuba-generated implementation has indeed similar performances as the reference one.
Yet another candidate to the LWC, Ace [8] provides two vectorized
implementations in its LWC submission: one for SSE and one for AVX. As
shown in the Scheduling post, Ace’s simeck_box function is bottlenecked
by its data dependencies. By fully inlining and unrolling the code,
Usubac is able to better schedule the code, thus removing any data
hazards, which translates in a 42% speedup on SSE and 50% on
AVX2. Alternatively, if code size matters, the developper can ask
Usubac to interleave Ace twice (using the -inter-factor 2 flag),
thus removing the need for unrolling and inlining, which produces a
smaller code, while remaining more than 30% faster than the reference
implementation.
Finally, Clyde [13] is a primitive used in the Spook submission to the LWC. A fast implementation for x86 CPUs is provided by the authors. However, because of data hazards in its linear layer, its IPC is only 2.87, while Usuba’s 3-interleaved optimization reaches an IPC of 3.59, which translates into a 29% speedup.
We also compared the Usuba implementations on general purpose registers of 3 candidates of the LWC that only provided naive implementations for x86. Those implementations were chosen because they were among the benchmarks of Tornado, and their reference implementations are sliced (unlike Photon and Spongent for instance: both of them rely on lookup tables), and therefore implementable in Usuba. In all 3 cases, Usubac-generated implementations are faster than the reference. While we do not pride ourselves in beating unoptimized implementations, this still hints that Usuba could be used by cryptographers to provide faster reference implementations with minimal effort.
| Mode | Cipher | Code size (SLOC) |
Throughput (cycles/bytes) |
Speedup | ||
|---|---|---|---|---|---|---|
| Ref | Usuba | Ref | Usuba | |||
| 32-vslicing | Pyjamask | 60 | 40 | 268.94 | 136.70 | +49.17% |
| 32-vslicing | Xoodoo | 51 | 53 | 6.30 | 5.77 | +8.41% |
| 32-vslicing | Gift | 52 | 65 | 523.90 | 327.13 | +37.56% |
Pyjamask [9] is slow when unmasked because of its expensive linear layer. After unrolling and inlining several nodes, Usubac’s msliced scheduler is able to interleave several parts of this linear layer, which were bottlenecked by data dependencies when isolated. The IPC of the Usuba-generated implementation is thus 3.92, while the reference one is only at 3.23.
Xoodoo [10] leaves little room for optimization: its register pressure is low enough to prevent spilling, but too high to allow interleaving. Some loops are bottlenecked by data dependencies, but C compilers automatically unroll them, thus alleviating the issue. As a result, Usuba is only 8% faster than the reference implementation. Furthermore, manually removing unnecessary copies from the reference implementation makes it perform on-par with Usuba. Still, Usuba can automatically generate SIMD code, which would easily outperform this x86-64 reference implementation.
Finally, Gift [11], similarly to Pyjamask, suffers from an expensive linear layer. By inlining it, Usubac is able to perform some computations at compile time, and once again, improves the IPC from 3.37 (reference implementation) to 3.93. Note that a recent technique called fixslicing [12] allows for a much more efficient implementation of Gift: Usuba’s fixsliced implementation performs at 38.5 cycles/bytes. However, no reference fixsliced implementation of Gift is available on x86 to compare ourselves with: the only fixsliced implementation available is written in ARM assembly. Also, note that despite its name, there is no relationship between bitslicing/mslicing as we them in Usuba and fixslicing. In fact, our fixsliced implementation of Gift is vsliced itself.
Scalability
The ideal speedup along SIMD extensions is bounded linearly by the
size of the registers. In pratice, spilling wider registers puts more
pressure on the L1 data-cache, leading to more frequent misses. Also,
AVX and AVX512 registers need tens of thousands warm-up cycles before
being used, since they are not powered when no instruction uses them
(this is not an issue for our benchmarks because we start by a warmup
phase). SSE instructions take two operands and overwrite one to store
the result, while AVX offer 3-operand non destructive instructions,
thus reducing register spilling. 32 AVX512 registers are available
against only 16 SSE/AVX ones, thus reducing the need for spilling. The
latency and throughput of most instructions differ from one
micro-architecture to another and from one SIMD to another. For
instance, up to 4 general purpose bitwise operations can be computed
per cycle, but only 3 SSE/AVX, and 2 AVX512. Finally, newer SIMD
extensions tend to have more powerful instructions than older
ones. For instance, AVX512 offers, among many useful features, 32-bit
and 64-bit rotations (vprold).
In the following, we thus analyze the scaling of our implementations on the main SIMD extensions available on Intel: SSE (SSE4.2), AVX, AVX2 and AVX512. Those benchmarks were compiled using Clang 9.0.1, and executed on a Intel(R) Xeon(R) W-2155 CPU @ 3.30GHz running a Linux 5.4.0. We distinguish AVX from AVX2 because the latter introduced shifts, n-bit integer arithmetic, and byte-shuffle on 256 bits, thus making it more suitable for slicing on 256 bits. Our results for bitslice ciphers follow:
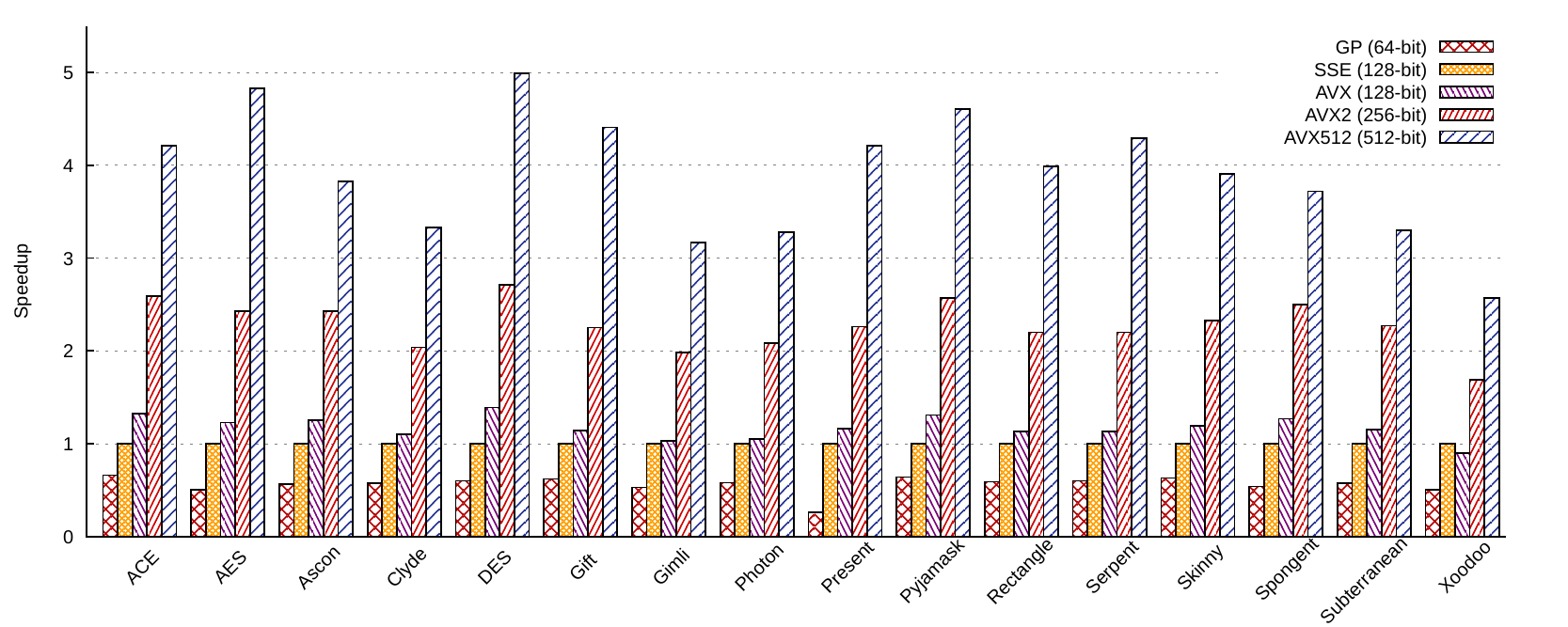
And for mslice ciphers:
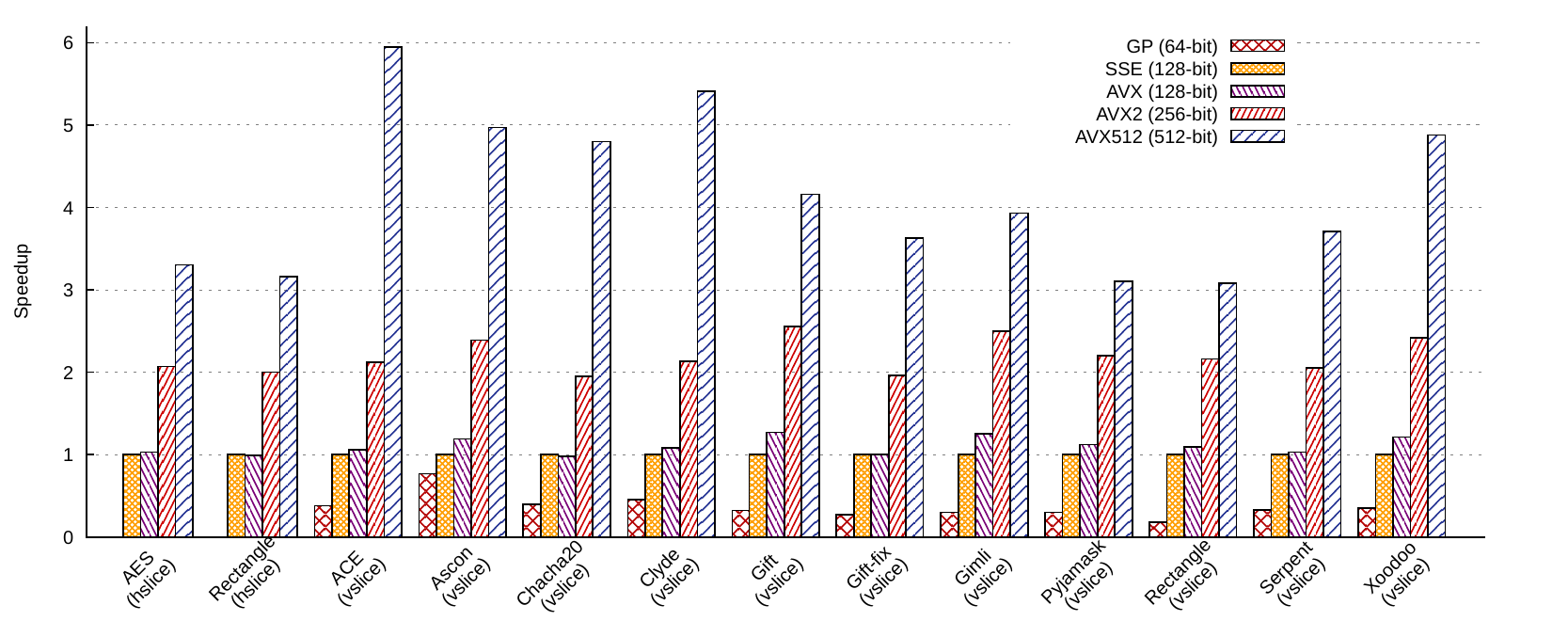
We omitted the cost of transposition in this benchmark to focus solely on the cryptographic primitives. The cost of transposition depends on the data layout and the target instruction set. For example, the transposition of uV16×4 costs 0.09 cycles/byte on AVX512 while the transposition of uH16×4 costs up to 2.36 cycles/byte on SSE.
Using AVX instructions instead of SSE (still filled with 128 bits of data though) increases the performances from 1% (eg. Rectangle vslice) up to 31% (ACE bitslice). AVX can offer better performance than SSE mainly because they provide 3-operand non-destructive instructions, whereas SSE only provides 2-operand instructions that overwrite one of their operands to store the results. Using AVX instructions thus reduces register pressure, which is especially beneficial for bitsliced implementations: DES, for instance, contains 3 times less memory operations on AVX than on SSE. Some vsliced ciphers are also faster thanks to AVX instructions, which is once again due to the reduced register pressure, in particular when interleaving –which puts a lot of pressure on the registers– is involved. Vsliced Ascon, Gimli and Xoodoo thus contains respecitvely 6, 2 and 2.5 times less memory operations on AVX than on SSE.
We observe accross all ciphers and slicing types that using AVX2 rather than AVX registers doubles the performances.
Doubling the size of the register once more by using AVX512 has a very
different impact depending on the ciphers, and is more complex to
analyze. First, while 3 arithmetic or bitwise AVX or SSE instructions
can be executed each cycles, it is limited to 2 on AVX512. Indeed, our
msliced AVX2 implementations have IPC above 3, while their AVX512
counterpart are closer to 2. This means that if Clang choses to use
equivalent instructions for AVX2 and AVX512 instructions (e.g.
_mm256_xor_si256 to perform a xor on AVX2, and _mm512_xor_si512
on AVX512), the throughput on AVX512 should only be 1.33 times greater
than on AVX2 (x2 because the registers are twice larger, but x2/3
because only 2 instruction can be executed each cycles instead of
3). However, only 1 shuffle can be executed each cycle regardless of
the SIMD instruction set (SSE, AVX2, AVX512), which mitigates this
effect on hslice ciphers. Thus, hslice Rectangle is 1.6x faster on
AVX512 than on AVX2 1 8th of its instructions are shuffles.
In addition to provide twice larger registers than AVX2, AVX512 also offer twice more registers (32 instead of 16), thus reducing the spilling. Those 16 additional registers reduce the spilling in AVX512 implementations compared to AVX2. Bitslice DES, Gift, Rectangle and AES thus contain respectively 18%, 20%, 32% and 55% less spilling than on AVX2, thus reaching 4 to 5 times the performances of the SSE impementations.
Similarly, hslice AES contains some spilling on AVX2, but none on AVX512, which translates into 13% less instructions on AVX512. Furthermore, 1 8th of its instructions are shuffles (which have the same throughput on AVX2 and AVX512). This translates into a x1.59 speedup on AVX512 compared to AVX2.
Using AVX512 rather than AVX2 however tends to increase the rate of cache-misses. For instance, on Gimli (resp. Xoodoo and Subterranean), 14% (resp. 18% and 19%) of memory loads are misses on AVX512, against less than 2% (resp. less than 3% and 1%) on AVX2. We thus observe that bitslice implementations of ciphers with large states, like Gimli (384-bits), Subterranean (257-bits), Xoodoo (384-bits), Photon (256-bits), generally scale worse than ciphers with small states, like DES (64-bits), AES (128-bits), Pyjamask (128-bits), Rectangle (64-bits) and Serpent (128-bits). An exception to this rule is Clyde, whose state is only 128-bits, but is only 1.63 faster on AVX512 than on AVX2: 21% of its memory accesses are misses on AVX512, and only 2% on AVX2. Another exception is ACE, whose state is 320-bits, and is 1.62 times faster on AVX512: only 4% of its memory accesses are misses on AVX512. Those effects are hard to predict since they depend both on the cipher, the compiler, and the hardware prefetcher.
The mslice ciphers that exhibit the best scaling on AVX512 (Chacha20, Ascon, Clyde, ACE, Xoodoo) all heavily benefit from the AVX512 rotate instructions. On older SIMD instruction sets (e.g. AVX2/SSE), rotations had to be emulated using 3 instructions:
// |x| is a 32-bit integer
x <<< n <===> (x << n) | (x >> (32-n))
Rotations amount for a more than a third of Clyde’s instructions, a third of Chacha20’s instructions are rotations, and a fourth of Ace, Ascon, Xoodoo’s instructions. For those 5 ciphers, AVX512 thus considerably reduce the amount of instructions compared to AVX2 and SSE, which translates into speedup of 4 to 5 times compared to SSE.
We propose to take the example of Serpent to go a provide a slighly more detailed explanation of the scaling. About 1 in 6 instructions of vsliced Serpent are rotations.Serpent contains only 13 spill-related move on AVX2, which, despite missing from the AVX512 implementation, have little impact on the performances. We can nicely compute the theoretical performances on Serpent on AVX512 compared to AVX2. Serpent contains 2037 bitwise and shift instructions, and 372 rotations. On AVX512, this corresponds to 2037 + 372 = 2409 instructions. On AVX2, rotations are emulated with 3 instructions, which causes the total of instructions to rise to 2037 + (372 * 3) = 3153. Since two AVX512 or three AVX2 instructions are executed each cycle, 2409 / 2 = 1205 cycles are required to compute the AVX512 version, and only 3153 / 3 = 1051 cycles for the AVX2 version. Since the AVX512 implementation computes twice many instances in parallel than on AVX2, the speedup of the AVX512 should thus be 1051 / 1205 * 2 = 1.74. In practice, we observe a speedup of x1.80. The few additional percents of speedup are partially due to a small approximation in the explanations above: we overlooked the fact that the round keys of Serpent are stored in memory, and that as many loads per cycles can be performed on AVX512 and AVX2.
Monomorphization
The relative performances of hslicing, vslicing and bitslicing vary from a cipher to another, and from an architecture to another. For instance, on Pyjamask, bitslicing is about 2.3 times faster than vslicing on SSE registers, 1.5 times faster on AVX, and as efficient on AVX512. On Serpent however, bitslicing is 1.7 times slower than vslicing on SSE, 2.8 times slower on AVX, and up to 4 times slower on AVX512.
As explained in the post describing the Usuba language, we can specialize our
polymorphic implementations to different slicing types and SIMD
instruction sets. Usuba thus allows to easily compare the performances
of the slicing modes of any cipher. In practice, few ciphers can be
not only bitsliced but also vsliced and hsliced: hslicing (except on
AVX512) requires the cipher to rely on 16-bit (or smaller) values,
arithmetic operations constraint ciphers to be only vsliced,
bit-permutations (declared with perm in Usuba) prevent efficient
vslicing, and often hslicing as well, etc.
One of the few ciphers compatible with all slicing types and all instruction sets (except hslicing on general purpose registers) is Rectangle. Its type in Usuba is:
node Rectangle(plain:u16x4, key:u16x4) returns (cipher:u16x4)
Compiling Rectangle for AVX2 in vsliced mode would produce a C implementation whose type would be:
void Rectangle (__m256i plain[4], __m256i key[26][4], __m256i cipher[4])
and which would compute 256/16=16 instances of Rectangle at once. Targetting instead SSE registers in bitsliced mode would produce a C implementation whose type would be:
void Rectangle (__m128i plain[64], __m128i key[26][64], __m128i cipher[64])
and which would compute 128 (the size of the registers) instances of Rectangle at once.
We leave for future work to modify Usuba’s auto-tuner to be able to compare all slicing types for the desired architecture.
In the following, we analyze the performances of vsliced, hsliced and bitsliced Rectangle on general purpose registers, SSE, AVX, AVX2 and AVX512; all of which were automatically generated from a single Usuba source of 31 lines. We ran this comparison on a Intel(R) Xeon(R) W-2155 CPU @ 3.30GHz, running Linux 5.4, and compiled the C codes with Clang 9.0.1.
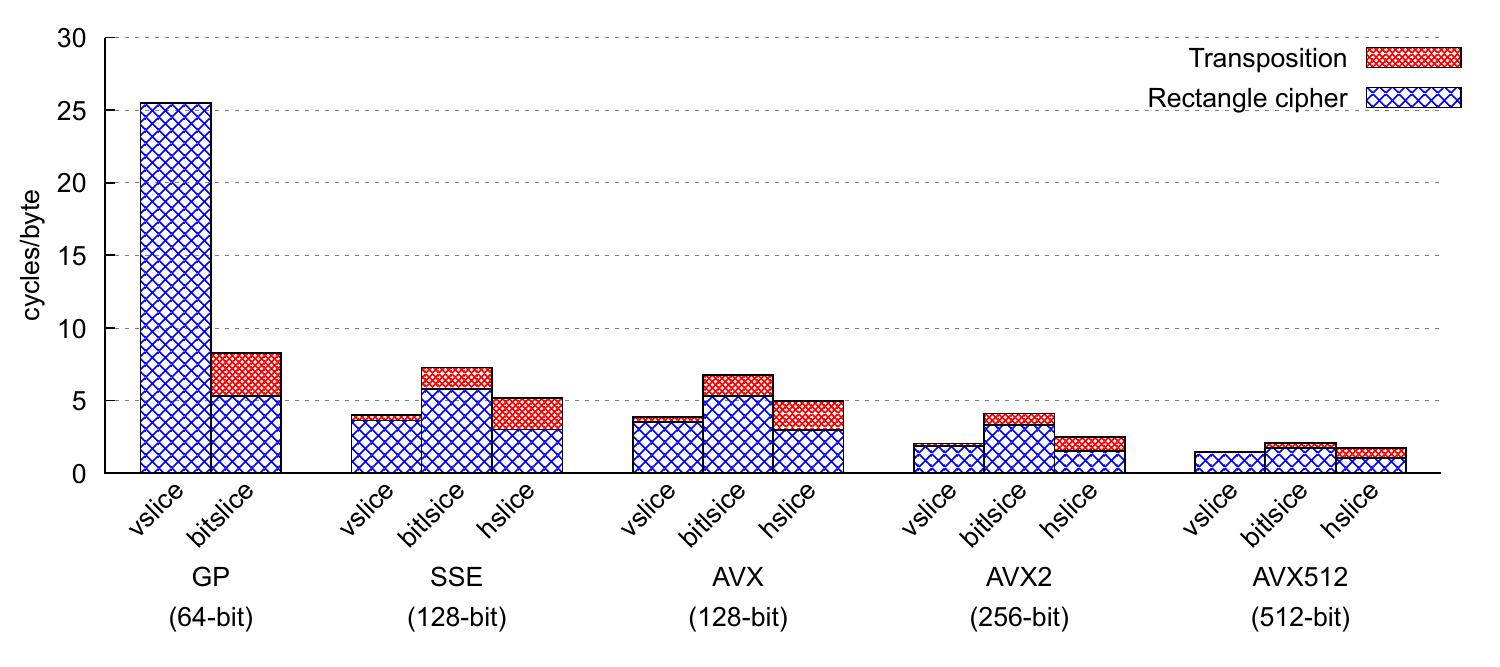
Overall, mslicing is more efficient that bislicing on Rectangle. The main reason is that it uses much less registers and thus do not require any spilling. Hslicing and vslicing do use more instructions per bit encrypted, since they perform the rotations of Rectangle’s linear layer at run-time (whereas they are computed at compile time by Usubac in bitslicing), but this small extra cost does not offset the improvement offered by their low register pressure.
When excluding the transposition, hslicing is faster than
vslicing. The main reason is that vsliced Rectangle requires 3
operations per rotation (since SSE and AVX do not offer rotate
instructions), whereas hsliced Rectangle only need one shuffle per
rotation. Without interleaving, both vsliced and hscliced Rectangle
would have similar performances however, because Skylake can only
perform one shuffle per round, and up to 3 shifts per round: the
shuffles would need to be computed sequentially, thus not fully
exploiting the superscalar pipeline. However, thanks to interleaving,
while the shuffles of one encryption are being computed
sequentially, the S-box of another (interleaved) encryption can be
computed at the same time (since it uses other ports of the CPUs).
On 64-bit general purpose registers, bitslicing is actually faster than vslicing because the latter processes only one block at a time, as a consequence of the lack of x86-64 instruction to shift 4 16-bit words in a single 64-bit register.
References
[1] National Bureau of Standards, Announcing the Data Encryption Standard, 1977.
[2] National Bureau of Standards. Announcing the Advanced Encryption Standard (AES), 2001.
[3] D. J. Bernstein, Chacha, a variant of Salsa20, SASC, 2008.
[4] E. Biham et al., Serpent: A New Block Cipher Proposal, FSE, 1998.
[5] W. Zhang et al., RECTANGLE: A Bit-slice Ultra-Lightweight Block Cipher Suitable for Multiple Platforms, 2014.
[6] D. J. Bernstein et al., Gimli: a cross-platform permutation, 2017.
[7] C. Dobraunig et al., Ascon, 2019.
[8] M. Aagaard et al., Ace: An Authenticated Encryption and Hash Algorithm, 2019.
[9] D. Goudarzi et al., Pyjamask, 2019.
[10] J. Daemen et al., Xoodoo cookbook, 2018.
[11] S. Banik et al., Gift: A Small Present, 2017.
[12] A. Adomnicai et al., Fixslicing: A New GIFT Representation, 2020.
[13] D. Bellizia et al., Spook: Sponge-Based Leakage-Resistant Authenticated Encryption with a Masked Tweakable Block Cipher, 2019.