Future directions for Usuba
Some future works were already discussed in previous posts:
implementing peephole optimizations for AVX512 (e.g. using
vpternlog) is discussed in the Backend post, and improving the performances on
embedded devices (e.g. by targeting assembly rather than C) is
discussed in the Tornado post. We propose in this post several additional
ideas to improve Usuba.
mslicing on general purpose registers
In Section Monomorphization of the Evaluation post, we mentioned that the lack of x86-64 instruction to shift 4 16-bit works in a single 64-bit register prevents us from parallelizing Rectangle’s vsliced implementation on general purpose registers.
In practice though, the _pdep_u64 intrinsic can be used to
interleave 4 independent 64-bit inputs of Rectangle in 4 64-bit
registers. This instruction takes a register a and an integer mask
as parameters, and dispatches the bits of a to a new registers
following the pattern specified in mask. For instance, using
_pdep_u64 with the mask 0x8888888888888888 would dispatch a 16-bit
input of Rectangle into a 64-bit register as follows:
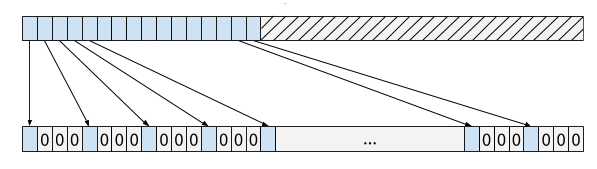
A second input of Rectangle could be dispatched into the next bits
using the mask 0x4444444444444444:
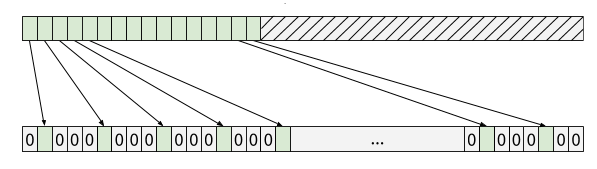
Repeating the process with two more inputs using the masks
0x2222222222222222 and 0x1111111111111111, and then combining the
results (using a simple or) would produce a 64-bit register
containing 4 interleaved 16-bit inputs of Rectangle. Since Rectangle’s
whole input is 64-bit, this process needs to be repeated 4
times. Then, regular shift and rotate instructions can be used to
independently rotate each input. For instance, a left-rotation by 2
can now be done by a simple left-rotation by 8:
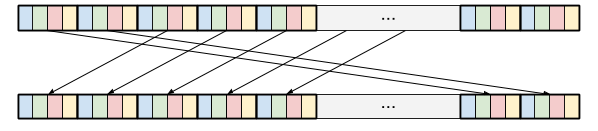
In essence, this technique relies on a data-layout inspired by hslicing (bits of the input are split along the horizontal direction of the registers), while offering access to a limit set of vslice instructions: bitwise instructions and shifts/rotates can be used, but arithmetic instructions cannot. We leave for future work the investigation of how this mode of slicing could be incorporated within Usuba in order to increase performance when vector extensions are not available.
Generalized mslicing
Recall the main computing nodes of Chacha20:
node QR (a:u32, b:u32, c:u32, d:u32)
returns (aR:u32, bR:u32, cR:u32, dR:u32)
let
a := a + b;
d := (d ^ a) <<< 16;
c := c + d;
b := (b ^ c) <<< 12;
aR = a + b;
dR = (d ^ aR) <<< 8;
cR = c + dR;
bR = (b ^ cR) <<< 7;
tel
node DR (state:u32x16) returns (stateR:u32x16)
let
state[0,4,8,12] := QR(state[0,4,8,12]);
state[1,5,9,13] := QR(state[1,5,9,13]);
state[2,6,10,14] := QR(state[2,6,10,14]);
state[3,7,11,15] := QR(state[3,7,11,15]);
stateR[0,5,10,15] = QR(state[0,5,10,15]);
stateR[1,6,11,12] = QR(state[1,6,11,12]);
stateR[2,7,8,13] = QR(state[2,7,8,13]);
stateR[3,4,9,14] = QR(state[3,4,9,14]);
tel
Within the node DR, the node QR is called 4 times on independent
inputs, and then 4 times again on independent inputs. Visually, we can
represent the first 4 calls to DR as:
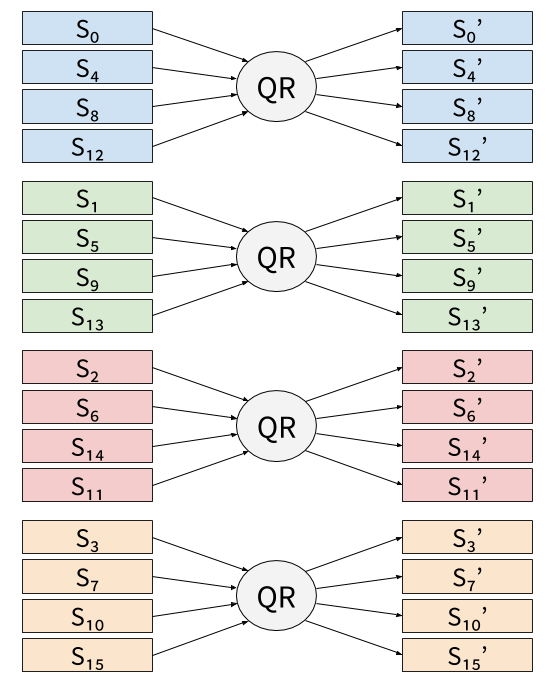
In vslicing, each 32-bit work of the state would be mapped to a SIMD register, and those registers would be filled with independent inputs. For instance, on SSE, 4 states would be processed in parallel:
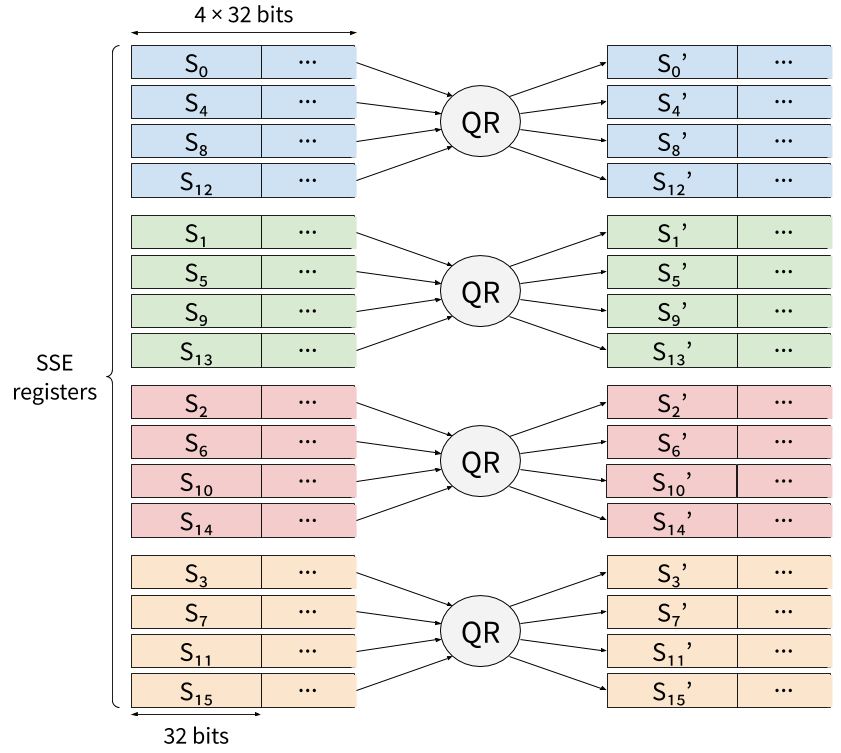
The last 4 calls to QR in the second half of DR would then be:
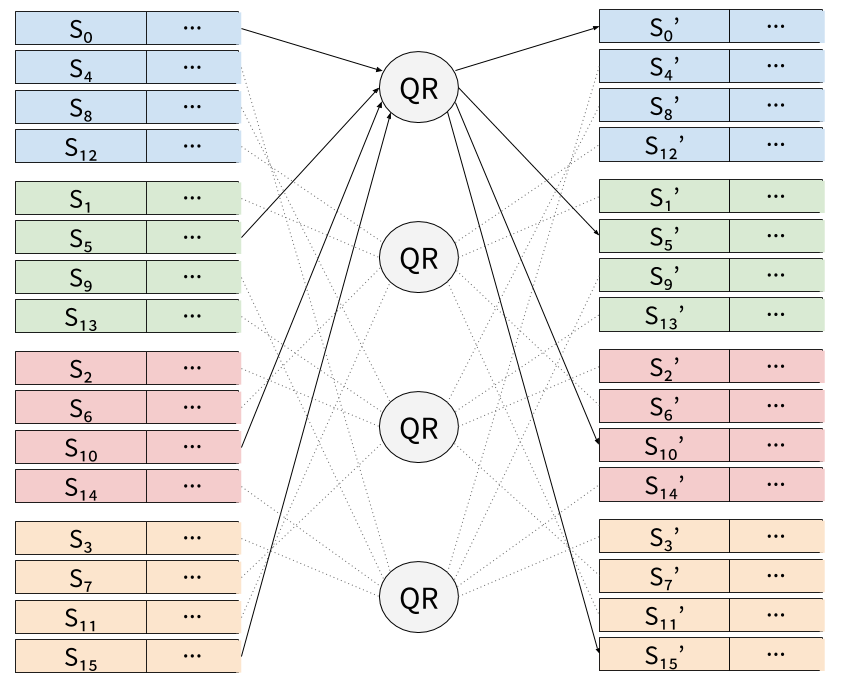
Using pure vslicing may be sub-optimal because 16 registers are required, which leaves no register for temporary variables on SSE or AVX. In practice, at least one register of the state will have to be spilled to memory.
Rather than parallelizing Chacha20 by filling SSE or AVX register with
independent inputs, it is possible to do the parallelization of a
single instance on SSE registers (respectively, two instances on
AVX2). Since the first 4 calls to QR operate on independent values,
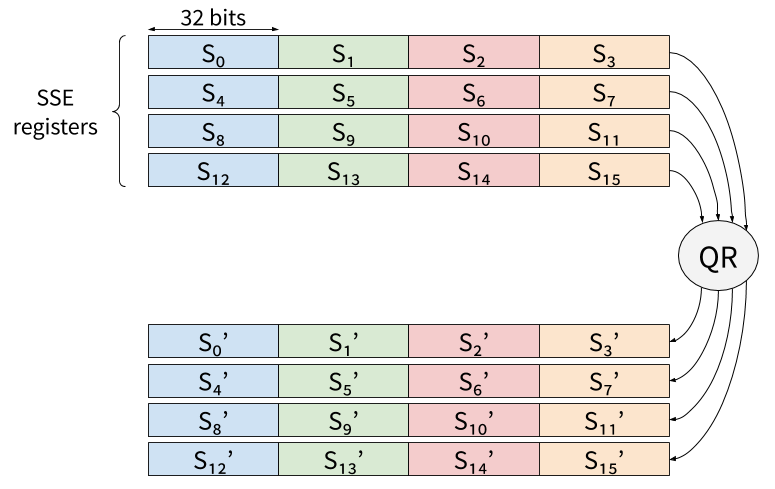
we can pack the 16 32-bit words of the state within 4 SSE (or AVX)
registers, and a single call to QR will compute it four times on a
single input:
Three rotations are then needed to reorganize the data for the final 4
calls to QR:
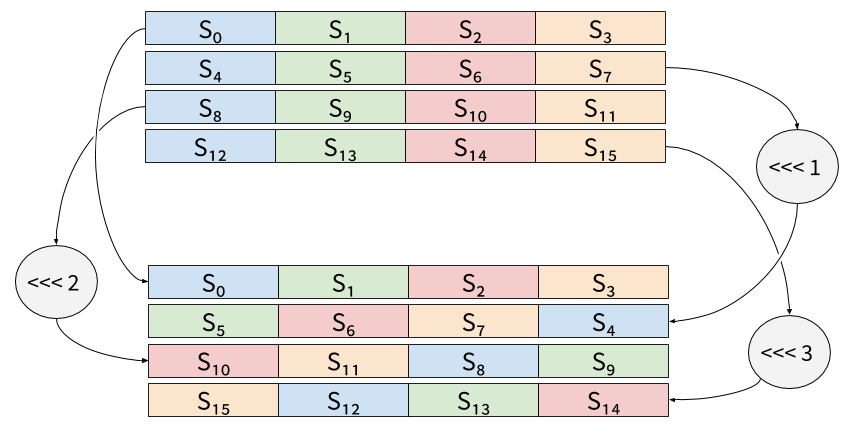
On SSE or AVX registers, those rotations would be done using Shuffle
instructions. Finally, a single call to QR computes the last 4
calls:
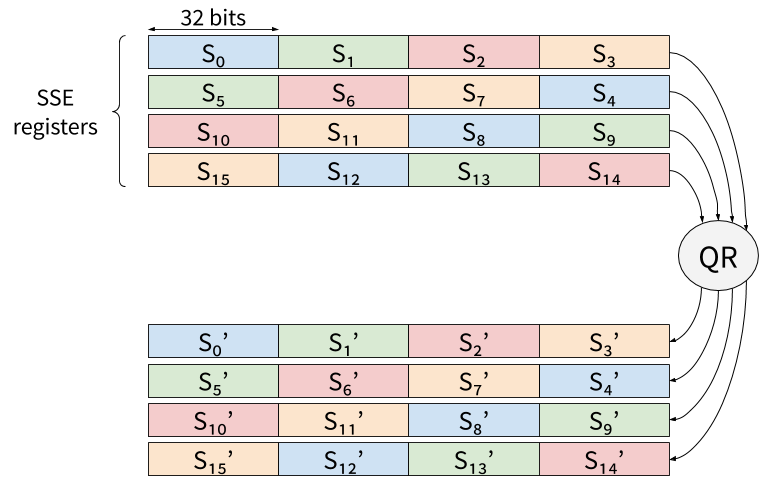
Compared to vslicing, this technique requires less independent inputs: on SSE (resp. AVX), it requires only 1 (resp. 2) independent inputs to reach the maximal throughput, while in vslicing, it requires 4 (resp. 8). Also, the latency is divided by 4 compared to vslicing, which will speed up applications that require encrypting less than 4 blocks.
The downside is that it requires additional shuffles to reorganize the
data withing each round and at the end of each round, which incurs an
overhead compared to vslicing. Furthermore, recall from the
Scheduling post that Chacha20’s quarter round (QR) is bound by
data-dependencies. In vslicing, Usuba’s scheduling algorithm is able
to interleave 4 quarter rounds, thus removing any stalls related to
data dependencies. This is not possible with this mixed sliced form,
since only two calls to QR remain, both of which cannot be computed
simultaneously.
However, a lower register pressure allows such an implementation of
Chacha20 to be implemented without any spilling, which improves
performance. Furthermore, because this implementation only uses 5
registers (4 for the state + 1 temporary), it could be interleaved 3
times without introducing any spilling. This interleaving would remove
the data hazards from QR. The performances of this spill-free
3-interleaved implementation (despite containing additional shuffles)
would need to be compared to the classical vsliced one. As shown in
the evaluation,
the fastest implementation of Gimli on AVX2 uses this technique, and
is faster than Usuba’s vsliced implementation.
We can understand this technique as an intermediary stage between
vertical and horizontal slicing. One way to incorpore it to Usuba
would be to represent atomic types with a word size m and a
vector size V (umV), instead of
a direction D and a word size m
(uDm). The word size would correspond
to the size of the packed elements within SIMD registers, and the
vector size would represent how many elements of a given input are
packed within the same input. For instance, Chacha20’s new
implementation would manipulate a state of 4 values of type
u324.
Using this representation, a vslice type
uVm would correspond to
um1, while an hslice type
uHm would correspond to
u1m, and a bitslice type
uD1 would unsurprisingly correspond to
u11.
A type umV would be valid only if the
targeted architecture offered SIMD vectors able to contain V words
of size m. Arithmetic instructions would be possible between two
umV values (provided that the
architecture offers instruction to perform m-bit arithmetics) and
shuffles would be allowed if the architectures offers instructions to
shuffle m-bit words.
Mode of operation
One of the commonly used mode of operation is counter mode (CTR). In
this mode (as illustrated below), a counter is encrypted by the
primitive (rather than encrypting the plaintext directly), and the
output of the primitive is xored with a block of plaintext to
produce the ciphertext. The counter is incremented by one for each
subsequent block of the plaintext to encrypt.
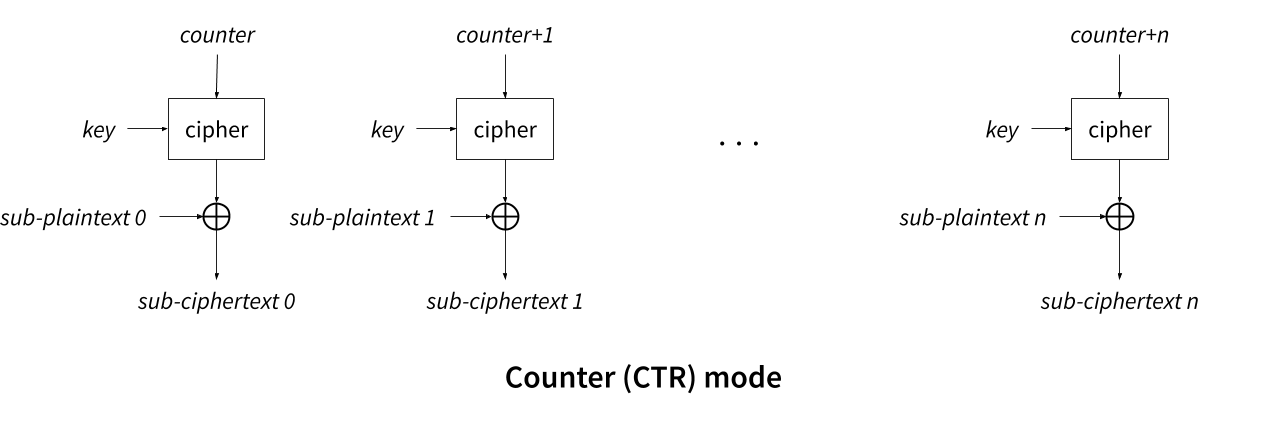
For 256 consecutives block to encrypt, only the last byte of the counter changes, and the other remain contant. Hongjun Wu and later Bernstein and Schwabe [1] observed that the last byte of AES’s input only impacts 4 bytes during the first round:
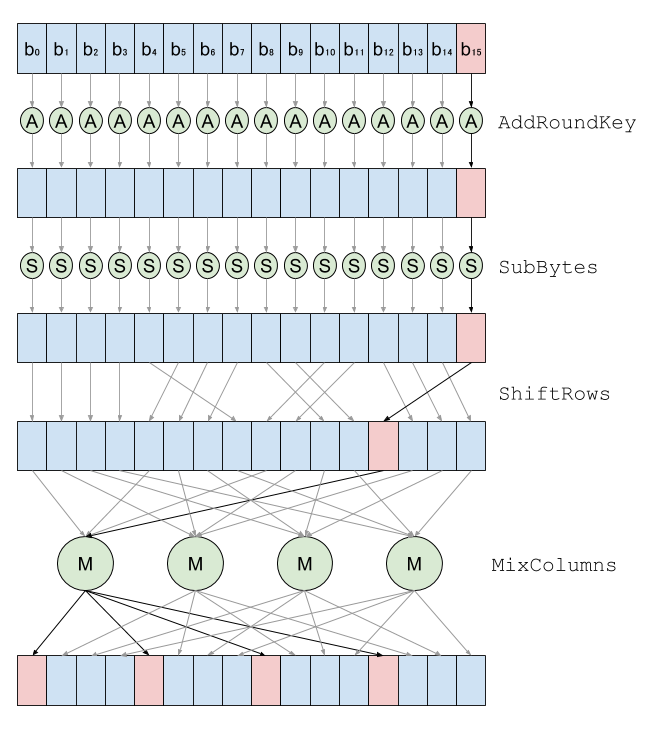
The results of the first round of AddRoundKey, SubBytes and
ShiftRows on the first 15 bytes, as well as MixColumns on 12 bytes
can thus be cached and reused for 256 encryptions. Concretely, the
first round of AES only require computing AddRoundKey and SubBytes
on a single byte (ShiftRows does not require computation), and
MixColumns on 4 bytes instead of 16. Similarly, 12 of the 16
AddRoundKey and SubBytes of the second round can be
cached. Additionally, Park and Lee [2] showed that some values can be
pre-computed to speed up computation even further (while keeping the
constant-time property of sliced implementations). Only 4 bytes of the
output of the first round depends on the last byte, which can take 256
values. Thus, it is possible to precompte all 256 possible values for
those 4 bytes (which can be stored a 1KB table (4 * 256 = 1KB)), and
reuse them until incrementing the counter past the 6th
least significant byte of the counter (b10 on the
figure above, which is an input of the same MixColumn as
b15), that is, once every 1 trillion block.
To integrate such optimizations in Usuba, we will have to broaden the scope of Usuba to support modes of operations: Usuba currently does not offer support statful computations and forces loops’ bounds to be known at compile-time. We would then need to extend the optimizer to exploit the specificities of Usuba’s new programming model.
Systematic Evaluation on Diverse Vectorized Architectures
We focused our evaluation of vectorization to Intel architectures, because of their wide availability. Other architectures, such as AltiVec on PowerPC and Neon on ARM, offer similar instructions as SSE and AVX. In particular, both AltiVec and Neon provide 128-bit registers supporting 8/16/32/64-bit arithmetic and shift instructions (used in vslicing), shuffles (used in hslicing) and 128-bit bitwise instructions (used in all slicing types). As a proof-of-concept, we thus implemented AltiVec and Neon backends in Usubac.
The figure below shows the speedup offered by vector extensions on a bitslice DES (including the transposition) on several architectures: SKL is our Intel Xeon W-2155 (with 64-bit general purpose registers, 128-bit SSE, 256-bit AVX2, 512-bit AVX512), PowerPC is a PPC 970MP (with 64-bit general purpose registers and 128-bit AltiVec), and ARMv7 is an ARMv7 Raspberry Pi3 (with 32-bit general purpose registers and 128-bit Neon). The performances have been normalized on each architecture to evaluate the speedups of vector extensions rather than the raw performances.
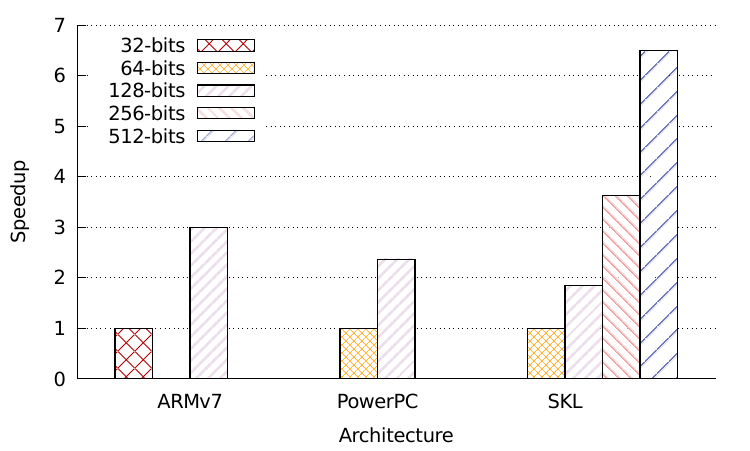
The speedups offered by SIMD extensions vary from one architecture to the other. PowerPC’s AltiVec offer 32-registers and 3-operand instructions, and thus expectedly perform better than Intel’s SSE comparatively to a 64-bit baseline. ARM’s Neon extensions only offer 16 registers on the other hand, resulting in a similar speedup as Intel’s AVX2 (note that ARMv7 has 32-bit registers whereas Skylake has 64-bit registers).
This benchmark only deals with bitslicing, and thus does not exploit arithmetic instructions, shuffles, or other architecture-specific SIMD instructions. We leave to future work to extend this preliminary evaluation to other ciphers and slicing modes.
Verification
Bugs in implementations of cryptographic primitives can have devastating consequences [9,10,11,12]. To alleviate the risk of such human errors, several recent projects aiming at generating cryptographic codes have adopted approaches ensuring the functionnal correctness of the code they produce [6,7,8].
The figure below illustrates how end-to-end functional correctness could be added to the Usubac compiler.
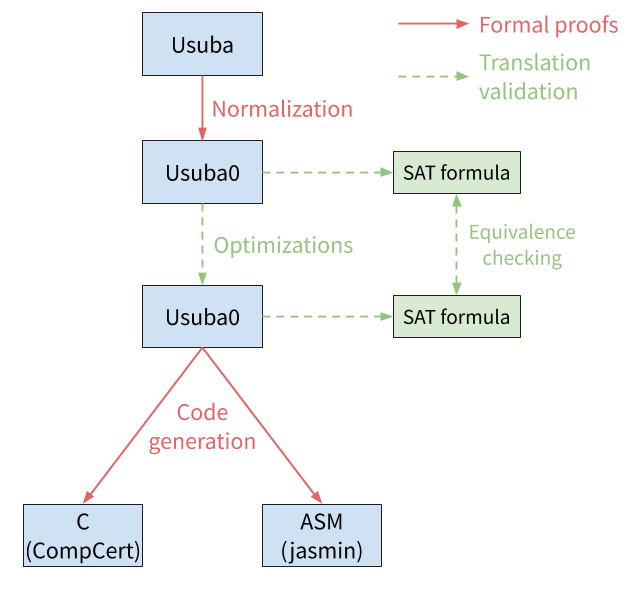
We propose to prove the correctness of the front-end by formaly proving that each each normalization pass preserves the semantics of the input program. Several work already showed how to prove the correctness of normalization of dataflow languages [3,13,14].
For the backend (optimizations), using translation validation [4] would certainly be more practical. The principle of translation validation is to check wether the program obtained after optimization has the same behavior as the program before optimization. This does not guarantee that the compiler is correct for all possible input programs, but it does guarantee that the compilation of a given program is correct. Translation validation leads to a more easily extensible compiler than proving the correctness of each pass, since adding a new pass of optimization does not impact the verification and does not require a proof of correctness for this pass.
We implemented a proof-of-concept translation validation for the optimizations of the Usubac compiler. The principle is simple: we extract two SAT formulas from the pipeline, one before the optimizations, and one after. We then feed them to the Boolector SMT solver [5], which checks wether they are equivalent (or, more precisely, wether an input exists such that feeding it to both formulas produces two distinct outputs). Extraction of a SAT formula from an Usuba0 program is straightforward thanks to our dataflow semantics: an Usuba0 program is simply a set of equations.
We used this translation validation approach to verify the correctness of our optimizations for Rectangle (bitslice and vslice), DES (bitslice), AES (bitslice), Chacha20 (vslice) and Serpent (vslice). In all cases, Boolector can able to confirm the equivalence of the programs pre and post-optimizations in less than a second, thus showing that this approach is practical (i.e. it can verify equivalence of Usuba0 programs in reasonable time) and requires little investement to be implemented.
For additional confidence in the translation validation approach, a certified SAT solver, such as SMTCoq [17], could be used.
Finally, translation from Usuba0 to imperative code can be formally verified using existing techniques of the dataflow community [3]. We could either target CompCert [15,16], a certified C compiler that produces x86 assembly code. Or, if we decide to generate assembly code ourselves (to improve performances, as motivated in the Tornado post), we can generate Jasmin assembly [7] and benefit from its mechanized semantics. In both cases (CompCert and Jasmin), some work might be required to support SIMD instruction sets.
GPU
A lot of implementations of cryptographic algorithms on graphics processing units (GPU) have been proposed in the last 15 years [18,19,20,21,22], including some implementation of bitslice DES [27,28,29] and bitslice AES [23,24,25,26,27]. Throughputs of more than 1 Tbits per seconds are reported for AES in [25]. The applications of such high-throughput implementations include, among others, password cracking [30,31], random number generation [32,33] or disk encryption [34,35].
Both bitslice [25,26,27] and mslice [23,24] implementations of AES have been demonstrated on GPUs. Additionally, Nishikawa et al. [24] showed that GPUs offer a large design space: computation is broken down into many threads, registers are a shared resource between threads, a limited amount of thread can be executed simultaneously… Nishikawa et al. [24] thus proposed an evaluation of the impact of some of those parameters on an msliced AES. Usuba could provide an oportunity to systematically explore this design space across a wide range of ciphers.
References
[1] D. J. Bernstein, P. Schwabe, New AES Software Speed Records, INDOCRYPT, 2008.
[2] J. H. Park, D. H. Lee, FACE: Fast AES CTR mode Encryption Techniques based on the Reuse of Repetitive Data, TCHES, 2018.
[3] T. Bourke et al., A Formally Verified Compiler for Lustre, PLDI, 2017.
[4] A. Pnueli et al., Translation validation, TACAS, 1998.
[5] A. Niemetz and al., Boolector 2.0 system description, Journal on Satisfiability, Boolean Modeling and Computation, 2015.
[6] J. K. Zinzindohoué et al., HACL*: A verified modern cryptographic library, ACM Conference on Computer and Communications Security, 2017.
[7] J. B. Almeida et al., Jasmin: High-Assurance and High-Speed Cryptography, CCS, 17.
[8] B. Bond et al., Vale: Verifying High-Performance Cryptographic Assembly Code, USENIX Security Symposium, 2017.
[9] B. B. Brumley et al., Practical realisation and elimination of an ECC-related software bug attack, CT-RSA, 2012.
[10] S. Gueron, V. Krasnov, The fragility of AES-GCM authentication algorithm, 2013.
[11] H. Boeck, Wrong results with Poly1305 functions, 2016.
[12] D. Benjamin, poly1305-x86.pl produces incorrect output, 2016.
[13] C. Auger et al., A Formalization and Proof of a Modular Lustre Compiler, 2012.
[14] C. Auger, Compilation certifiée de SCADE/LUSTRE, 2013.
[15] S. Blazy et al., Formal verification of a C compiler front-end, FM, 2006.
[16] X. Leroy, Formal verification of a realistic compiler, Communications of the ACM, 2009.
[17] M. Armand et al., A modular integration of SAT/SMT solvers to Coq through proof witnesses, CPP, 2011.
[18] S. A. Manavski et al., CUDA compatible GPU as an efficient hardware accelerator for AES cryptography, ICSPC, 2007.
[19] R. Szerwinski, T. Gïneysu, Exploiting the Power of GPUs for Asymmetric Cryptography, CHES, 2008.
[20] D. A. Osvik et al., Fast Software AES Encryption, FSE, 2010.
[21] O. Harrison, J. Waldron, Efficient Acceleration of Asymmetric Cryptography on Graphics Hardware, AFRICACRYPT, 2009.
[22] D. Cook et al., CryptoGraphics: Secret key cryptography using graphics cards, CT-RSA, 2005.
[23] R. K. Kim et al., Bitsliced High-Performance AES-ECB on GPUs, The New Codebreakers, 2016.
[24] N. Nishikawa et al., Implementation of Bitsliced AES Encryption on CUDA-Enabled GPU, NSS, 2017.
[25] O. Hajihassani et al., Fast AES Implementation: A High-throughput Bitsliced Approach, IEEE Transactions on Parallel and Distributed Systems, 2019.
[26] B. Peccerillo et al., Parallel bitsliced AES through PHAST: a single-source high-performance library for multi-cores and GPUs, Journal of Cryptographic Engineering, 2019.
[27] J. Yang, J. Goodman, Symmetric Key Cryptography on Modern Graphics Hardware, ASIACRYPT, 2007.
[28] N. Dennier et al., Improved Software Implementation of DES Using CUDA and OpenCL, 2011.
[29] G. Agosta et al., Record setting software implementation of DES using CUDA, 2010.
[30] L. Sprengers, GPU-based password cracking, 2011.
[31] M. Bakker, R. Van Der Jagt, GPU-based password cracking, 2010.
[32] S.K. Monfared et al., High-performance Cryptographically Secure Pseudo-random Number Generation via Bitslicing, 2019.
[33] W.K. Lee et al., Fast implementation of block ciphers and PRNGs in Maxwell GPU architecture, Cluster Computing, 2016.
[34] G. Agosta et al., Fast disk encryption through GPGPU acceleration, PDCAT, 2009.
[35] W. Sun et al., GPUstore Harnessing GPU Computing for Storage Systems in the OS Kernel, SYSTOR, 2012.