Tornado, Automatic Generation of Probing-Secure Masked Sliced Implementations
CPU leak information through timing [49], caches accesses [52,53,54], power consumption [48,49,42], electromagnetic radiations [45,46,47] and other compromising emanations [50,51]. A way to recover this leaked information is to design a Simple Power Analysis (SPA) or a Differential Power Analysis (DPA) attack [23], which work by analyzing power or EM traces from a cipher’s execution to recover the key and plaintext.
Several approaches to mitigate SPA and DPA have been proposed. This includes inserting dummy instructions, working with both data and their complements, using specific hardware modules to randomize power consumption [40], or designing hardware gates whose power consumption is independent of their inputs [32,41]. The most popular countermeasure against SPA and DPA, called masking, is however based on secret sharing [24,25]. Masking, unlike some other countermeasures mentionned above, does not require custom hardware, and offers provable security: given an attacker model, one can prove that a masked code does not leak any secret data.
Masking
The first masking schemes were proposed by Chari et al. [38] and
Goubin and Patarin [39]. The principle of masking is to split each
intermediate value b of a cipher into k random values r1 … rk
(called shares) such that b = r1 ∗ r2 ∗ ... ∗ rk for some group
operation ∗. The most commonly used operation is the exclusive or
(Boolean masking), but modular addition or modular multiplication
can also be used (arithmetic masking) [28,26].
A masked implementation using 2 shares is said to be first-order masked. Early masked implementations were only first-order masked [28,26,37,27], which is sufficient to protect against first-order DPA. However, higher order DPA (HO-DPA) can be designed by combining multiple sources of leakage to reconstruct the secrets, and can break first-order masked implementations [23,42,55,56]. Several masked implementations using more than two shares (higher-order masking) where thus proposed to resist HO-DPA [29,63,65,66,68]. The term masking order is used to refer to the number of shares minus one. Similarly, an attack is said to be of order t if it combines t sources of leakage.
The probing-model is widely used to analyze the security of masked software implementations against side-channel attacks. This model was introduced by Ishai, Sahai and Wagner in [29] to construct circuits resistant to hardware probing attacks. It was latter shown [63,68,64] that this model and the underlying constructions were instrumental to the design of efficient secure masked cryptographic implementations. A masking scheme is secure against a t-probing adversary, i.e. an adversary who can probe t arbitrary variables during the computation, is indeed secure by design against the class of side-channel attacks of order t [91].
Most masking schemes consider the cipher as a Boolean or arithmetic circuit. Individual gates of the circuit are replaced by gadgets that process masked variables. One of the important contributions of [29] was to propose a multiplication gadget secure against t-probing attacks for any t, based on a Boolean masking of order n = 2t+1. This was reduced to the tight order n = t+1 in [66] by constraining the two input sharings to be independent, which could be ensured by the application of a mask-refreshing gadget when necessary. The design of secure refresh gadgets and, more generally, the secure composition of gadgets were subsequently subject to many works [64,87,92]. Of particular interest, the notions of Non-Interference (NI) and Strong Non-Interference (SNI) introduced in [87] provide a practical framework for the secure composition of gadgets that yields tight probing-secure implementations. In a nutshell, such implementations are composed of ISW multiplication and refresh gadgets (from the names oftheir inventors Ishai, Sahai, and Wagner [48]) achieving the SNI property, and of sharewise addition gadgets. The main difficulty consists in identifying the minimal number of refresh gadgets and their (optimal) placing in the implementation to obtain a provable t-probing security.
Terminology. In the context of a Boolean circuit, multiplications
correspond to and and or gates, while additions correspond to
xor gates. Multiplications (and therefore and and or) are said
to be non-linear, while additions (and therefore xor) are said to
be linear.
Tornado
Belaïd et al. [72] developed a tool named tightPROVE, which is able to verify the t-probing security of a masked implementation at any order t. This verification is done in the bit probing model, meaning that each probe only retrieves a single bit of data. It is thus limited to verify the security of programs manipulating 1-bit variables. Raphaël Wintersdorff, Sonia Belaïd, and Matthieu Rivain recently developped tightPROVE+, an extension of tightPROVE to the register probing model where variables can hold an arbitrary number of bits, all of which leak simultaneously. Futhermore, tightPROVE+ automatically insert refreshes when needed, whereas tightPROVE was only able to detect that some refreshes were missing. We worked with them to integrate tightPROVE+ with Usuba [90]. The resulting tool is called Tornado. Tornado generates provably t-probing secure masked implementations in both the bit-probing and the register-probing model.
Given a high-level description of a cryptographic primitive, Tornado synthesizes a masked implementation using ISW-based multiplication and refresh gadgets [1], and sharewise addition gadgets. The key role of Usuba is to automate the generation of a sliced implementation, upon which tightPROVE+ is then able to verify either the bit probing or register probing security, or suggest the necessary refreshes. By integrating both tools, we derive a probing-secure masked implementation from a high-level description of a cipher.
The overall architecture of Tornado is shown below:
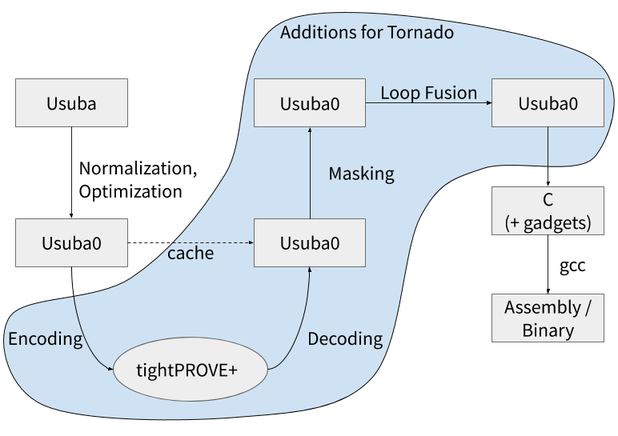
After normalization and optimization, the Usuba0 program is sent to tightPROVE+, which adds refreshes if necessary. The output of tightPROVE+ is translated back to Usuba0, which Usubac then masks: variables are replaced with arrays of shares, linear operators and non-linear operators involving constants are applied share-wise, and other non-linear operators and refreshes are left as is to be replaced by masked gadgets during C code generation. Before generating C code, a pass of loop fusion merges share-wise applications of linear operators when possible.
Encoding and Decoding Usuba0 for tightPROVE+
Tornado targets low-end embedded devices with drastic memory constraints. It is therefore essential to produce a C code that uses loops and functions, in order to reduce code size, especially when masking at high orders. This is one of the main motivation to keep loops and nodes in the Usuba pipeline despite their semantics being defined through macro-expansion to straightfoward equations.
However, tightPROVE+ only supports straight line programs, providing no support for loops and functions. Usubac thus fully unrolls and inlines the Usuba0 code before interacting with tightPROVE+. The refreshes inserted by tightPROVE+ must then be propagated back into the Usuba0 program, featuring loops, nodes and node calls.
To do so, when inlining and unrolling, we keep track of the origin of each instruction: which node they come from, and which instruction in that node. For each refresh inserted by TightPROVE+, we therefore know where (i.e., which node and which loop, if any) the refreshed variable comes from, and are therefore able to insert the refresh directly in the right node.
In order to help tightPROVE+ to find where to insert refreshes, a first pass sends each node (before inlining) to tightPROVE+ for verification. Those nodes are smaller than the fully inlined program, and tightPROVE+ is thus faster to detect the required refreshes. Only then are all nodes inlined and the whole program is sent to tightPROVE+. This is useful for instance on Ace, which contains the following node:
node f(x:u32) returns (y:u32)
let
y = ((x <<< 5) & x) ^ (x <<< 1)
tel
This node is obviously vulnerable to probing attacks, and
tightPROVE+ is able to insert a refresh on one of the x
to make it probing-secure. Once the secure version of f is inlined
in Ace, no other refreshes are needed.
Since tightPROVE+’s verification often takes hours or even days to verify a whole cipher [3], Usubac uses a cache to avoid calling tightPROVE+ multiple times on the same circuit.
Masking
To mask an Usuba0 program, Usubac replaces each variable with an array
of shares, and each operator with a masked gadget. The gadget to mask
a linear operator (xor) is simply a loop applying the operator on
each share, written directly in Usuba. To mask a negation, we only
negate the first share (since ~(r0 ^ r1 ^ ... ^ rk) == ~r0 ^ r1 ^
... ^ rk), still in Usuba. To mask non-linear operators (and and
or), however, we introduce the operators m& and m| in Usuba,
which are transformed into calls to masked C gadgets when generating C
code. In particular, for the multiplication (and), we use the
so-called ISW gadget introduced in [1]:
static void isw_mult(uint32_t *res,
const uint32_t *op1,
const uint32_t *op2) {
for (int i = 0; i <= MASKING_ORDER; i++)
res[i] = 0;
for (int i = 0; i <= MASKING_ORDER; i++) {
res[i] ^= op1[i] & op2[i];
for (int j = i+1; j <= MASKING_ORDER; j++) {
uint32_t rnd = get_random();
res[i] ^= rnd;
res[j] ^= (rnd ^ (op1[i] & op2[j])) ^ (op1[j] & op2[i]);
}
}
}
Note that this algorithm has a quadratic complexity in the number of
shares. ors are transformed into not and and, since a | b ==
~(~a & ~b). Similarly, refreshes, either inserted manually by the
developper or automatically by tightPROVE+, are compiled
into calls to the ISW refresh routine when generating C code:
static void isw_refresh(uint32_t *res,
const uint32_t *in) {
for (int i=0; i<=MASKING_ORDER; i++)
res[i] = in[i];
for (int i=0; i<=MASKING_ORDER; i++) {
for (int j=i+1; j<=MASKING_ORDER; j++) {
uint32_t rnd = get_random();
res[i] ^= rnd;
res[j] ^= rnd;
}
}
}
Constants
Constants are not secret values and thus do not need to be shared. Furthermore, when multiplying a constant with a secret value, there is no need to use the ISW mutliplication gadgets: we can simply multiply each share of the secret value with the constant. The cost of masking a multiplication by a constant is thus linear in the number of shares, rather than quadratic. Our benchmarks (see section “Evaluation” below) show that indeed, the more masked multiplication a cipher has, the slower it is. Avoiding unnecessary masked multiplications is thus essential.
For instance, Pyjamask’s linear layer contains a matrix
multiplication, implemented by calling 4 times the following Usuba
node, which multiplies two 32-bit vectors a and b:
node col_mult (a:b32,b:b32) returns (r:b1)
vars acc:b32
let
acc[0] = a[0] & b[0];
forall i in [1,31] {
acc[i] = acc[i-1] ^ (a[i] & b[i])
}
r = acc[31]
tel
When this node is called in Pyjamask, b is always constant, and the
multiplication (a[i] & b[i]) therefore does not need to be
masked. Usubac uses a simple inference algorithm to track which
variables are constant and which are not, and is thus able to identify
that b does not need to be shared, and that the multiplication a[i]
& b[i] does not need to be masked. This optimization both reduces
stack usage (since constant variables are kept as a single share
rather than an array of shares) and increases performances (since
multiplying by a constant becomes linear rather than quadratic).
Loop Fusion
Since each linear operation is replaced with a loop applying the operation on each share, the masked code contains a lot of loops. The overhead of those loops is detrimental to performances. Consider for instance the following Usuba0 snippet:
x = a ^ b;
y = c ^ d;
z = x ^ y;
After masking, it becomes:
forall i in [0, MASKING_ORDER-1] {
x[i] = a[i] ^ b[i];
}
forall i in [0, MASKING_ORDER-1] {
y[i] = c[i] ^ d[i];
}
forall i in [0, MASKING_ORDER-1] {
z[i] = x[i] ^ y[i];
}
In order to reduce the overhead of looping over each share for linear operations, we aggressively perform loop fusion (also called loop jamming) in Usubac, which consists in replacing multiple loops with a single one. The above snippet is thus optimized to:
forall i in [0, MASKING_ORDER-1] {
x[i] = a[i] ^ b[i];
y[i] = c[i] ^ d[i];
z[i] = x[i] ^ y[i];
}
Loop fusion is also able to reduce the amount of stack used by
allowing Usubac to replace temporary arrays with temporary
variables. In the example above, Usubac would thus convert x and y
into scalars rather than arrays and produce the following code:
forall i in [0, MASKING_ORDER-1] {
x = a[i] ^ b[i];
y = c[i] ^ d[i];
z[i] = x ^ y;
}
On embedded devices (which Tornado targets), this is especially beneficial since the amount of stack available is very limited (e.g. a few dozen of kilobytes).
C compilers also perform loop fusion, but experimentally, they are less aggressive than Usubac. We thus obtain better performances by fusing loops directly in Usubac. On the 11 ciphers of the NIST competition we implemented in Usuba and compiled with Tornado, performing loop fusion in Usubac allows us to reduce stack usage of our bitsliced implementations by 11kB on average whereas this saves us, on average, 3kB of stack for our msliced implementations (note that our platform offers a measly 96kB of SRAM). It also positively impacts performance, with a 16% average speedup for bitslicing and a 21% average speedup for n-slicing.
Evaluation
We used Tornado to compare 11 cryptographic primitives from the second round of the ongoing NIST lightweight cryptography competition (LWC). The choice of cryptographic primitives was made on the basis that they were self-identified as being amenable to masking. We stress that we do not focus on the full authenticated encryption, message authentication, or hash protocols but on the underlying primitives, mostly block ciphers and permutations. The complete list of primitives follows:
| submissions | primitive | msliceable | slice size |
|---|---|---|---|
| block ciphers | |||
| Gift-Cofb [7], Hyena [17], Sundae-Gift [18] |
Gift-128 | ✔ | 32 |
| Pyjamask [10] | Pyjamask-128 | ✔ | 32 |
| Skinny [11], Romulus [19] |
Skinny-128-256 | ✖ | - |
| Spook [6] | Clyde-128 | ✔ | 32 |
| permutations | |||
| Ace [4] | Ace | ✔ | 32 |
| Ascon [5] | p12 | ✔ | 64 |
| Elephant [13,12] | Spongent-π[160] | ✖ | - |
| Gimli [8] | Gimli-36 | ✔ | 32 |
| Orange [20], Photon-Beetle [9] |
Photon-256 | ✖ | - |
| Xoodyak [15,16] | Xoodoo | ✔ | 32 |
| others | |||
| Subterranean [14] | blank(8) | ✖ | - |
Whenever possible, we generate both a bitsliced and an n-sliced implementation for each primitive, which allows us to exercise the bit-probing and the register-probing models of tightPROVE+. However, 4 primitives do not admit a straightforward n-sliced implementation. The Subterranean permutation involves a significant amount of bit-twiddling across its 257-bit state, which makes it a resolutely bitsliced primitive (as confirmed by its reference implementation). Photon, Skinny, Spongent rely on lookup tables that would be too expansive to emulate in n-sliced mode. In bitslicing, these tables are simply implemented by their Boolean circuit, either provided by the authors (Photon, Skinny) or generated through SAT [2] with the objective of minimizing multiplicative complexity (Spongent, with 4 ANDs and 28 XORs).
Note that the n-sliced implementations, when they exist, are either 32-sliced or 64-sliced. This means in particular that, unlike bitslicing that allows processing multiple blocks in parallel, these implementations process a single block at once on our 32-bit Cortex M4. Note also that in practice, all n-sliced implementation are vsliced, since the Cortex M4 we consider does not provide SIMD extensions, which are required for hslicing.
Running tightPROVE+ on our Usuba implementations showed that all of them were t-probing secure in the bit-probing model, but 3 were not secure in the register-probing model. ACE required 384 additional refreshes, Clyde-128 required 6 refreshes, and Gimli required 120. In the case of ACE and Clyde, the number of refreshes inserted by tightPROVE+ is known to be minimal, while for Gimli, it is only an upper bound [3].
Baseline Performance Evaluation
In the following, we benchmark our implementations –written in Usuba and compiled by Tornado– of the NIST submissions against the reference implementation provided by the contestants. This allows us to establish a performance baseline (without masking), thus providing a common frame of reference for the performance of these primitives based on their implementation synthesized from Usuba. In doing so, we have to bear in mind that the reference implementations provided by the NIST contestants are of varying quality: some appear to have been finely tuned for performance while others focus on simplicity, acting as an executable specification.
Several candidates of the NIST LWC do not provide implementations for
ARM devices. However, since they all provide a reference (generic) C
implementation, we first benchmarked our implementations against the
reference implementations on an Intel i5-6500 @ 3.20GHz, running Linux
4.15.0-54. The implementations were compiled with Clang 7.0.0 with
flags -O3 -fno-slp-vectorize -fno-vectorize. These flags prevent
Clang from trying to produce vectorized code, which would artificially
advantage some implementations at the expense of others because of
brittle, hard-to-predict vectorization heuristics. Besides, vectorized
instructions remain an exception in the setting of embedded devices
(e.g., Cortex M). At the exception of Subterranean (which is
bitsliced), the reference implementations follow an msliced
implementation pattern, representing the state of the primitive
through a matrix of 32-bit values, or 64-bit in the case of Ascon. To
evaluate bitsliced implementations, we simulate a 32-bit architecture,
meaning that the throughput we report corresponds to the parallel
encryption of 32 independent blocks. The cost of transposing data into
a bitslice format (around 9 cycles/bytes to transpose a 32x32 matrix)
is excluded. The results are shown in the following table:
| Primitive | Performances (cycles/bytes) (lower is better) |
||
|---|---|---|---|
| Usuba n-slice | Usuba bitslice | reference | |
| Ace | 34.25 | 55.89 | 273.53 |
| Ascon | 9.84 | 4.94 | 5.18 |
| Clyde | 33.72 | 21.99 | 37.69 |
| Gimli | 15.77 | 5.80 | 44.35 |
| Gift | 565.30 | 45.51 | 517.27 |
| Photon | - | 44.88 | 214.47 |
| Pyjamask | 246.72 | 131.33 | 267.35 |
| Skinny | - | 46.87 | 207.82 |
| Spongent | - | 146.93 | 4824.97 |
| Subterranean | - | 17.64 | 355.38 |
| Xoodoo | 14.93 | 6.47 | 10.14 |
We notice that Usuba often delivers performance that is on par or better than the reference implementations. Note that this does not come at the expense of readability: our Usuba implementations are written in a high-level language, which is amenable to formal reasoning thanks to its straightforward semantics model. The reference implementations of Skinny and Photon use lookup tables, which do not admit a straightforward implementation constant-time. As a result, we are unable to implement a constant-time msliced version in Usuba and to mask such an implementation.
We now turn our attention specifically to a few implementations that exhibit interesting performance.
The reference implementation of Subterranean is an order of magnitude slower than in Usuba because its implementation is bit-oriented (each bit is stored in a distinct 8-bit variable) but only a single block is encrypted at a time. Switching to 32-bit variables and encrypting 32 blocks in parallel, as Usuba does, significantly improves performance.
The reference implementation of Spongent is slowed down by a prohibitively expensive 160-bit bit-permutation, which is spread across 20 8-bit variables. Thanks to bitslicing, Usuba turns this permutation into a static renaming of variable, which occurs at compile-time.
On Ascon, our n-sliced implementation is twice slower than the reference implementation. Unlike the reference implementation, we have refrained from performing aggressive function inlining and loop unrolling to keep code size in check, since we target embedded systems. However, if we instruct the Usuba compiler to perform these optimizations, the performance of our n-sliced implementation is on par with the reference one.
Ace reference implementation suffers from significant performance issues, relying on an excessive number of temporary variables to store intermediate results.
Gimli offers two reference implementations, one being a high-performance SSE implementation with the other serving as an executable specification on general-purpose registers. We chose the general-purpose one here (which had not been subjected to the same level of optimizations) because our target architecture (Cortex M) does not provide a vectorized instruction set.
Finally, Gift’s n-slice implementation suffers from sever performance issues because of its expensive linear layer. Using the recent fixslicing technique [21] improves the performance of Usuba’s n-slice Gift implementation down to 42 cycles/byte.
Masking benchmarks
We ran our benchmarks on a Nucleo STM32F401RE offering an Arm Cortex-M4 with 512 Kbytes of Flash memory and 96 Kbytes of SRAM. We used the GNU C compiler arm-none-eabi-gcc version 9.2.0 at optimization level -O3. We considered two modes regarding the Random Number Generator (RNG):
-
Pooling mode: The RNG generates random numbers at a rate of 32 bits every 64 clock cycles. Fetching a random number can thus take up to 65 clock cycles.
-
Fast mode: The RNG has a production rate faster than the consumption rate of the program. The RNG routine thus can simply read a register containing this 32-bit random word without checking for its availability.
Those two modes were chosen because they are the ones used in the Pyjamask submission, which is the only submission addressing the issue of getting random numbers for a masked implementation.
Scaling
N-slicing
The table bellow gives the performances of the n-sliced implementations produced by Tornado in terms of cycles per block. Note that this does not reflect the performances in term of cycles/bytes, since those ciphers have different block size. For instance, encrypting a single block with Xoodoo is more than twice slower than with Clyde (at any given order), but since Xoodoo’s block is 384 bits, while Clyde’s is only 128 bits, the performances of Xoodoo in terms of cycles/bytes are better than Clyde’s. Nevertheless, we focus here on the performances per block, and analyze the performances per bytes in the next section, when considering bitsliced implementations.
| primitive | mults | RNG mode |
Performances (cycles) (lower is better) |
||||||
|---|---|---|---|---|---|---|---|---|---|
| d = 0 | d = 3 | d = 7 | d = 15 | d = 31 | d = 63 | d = 127 | |||
| Clyde | 48 | fast | 1.47k | 15.38k | 56.48k | 189.44k | 670.08k | 2.58m | 10.45m |
| pooling | 1.47k | 30.08k | 121.08k | 502.88k | 1.94m | 7.73m | 29.92m | ||
| Pyjamask | 56 | fast | 15.90k | 79.52k | 205.44k | 614.40k | 1.73m | 4.75m | 15.20m |
| pooling | 15.90k | 94.88k | 274.56k | 954.56k | 3.10m | 10.34m | 36.32m | ||
| Ascon | 60 | fast | 1.96k | 42.00k | 123.20k | 464.40k | 1.70m | 6.52m | 25.60m |
| pooling | 1.96k | 53.60k | 182.80k | 821.60k | 3.17m | 12.96m | 52.00m | ||
| Xoodoo | 144 | fast | 3.02k | 42.67k | 156.48k | 520.32k | 1.89m | 6.86m | 26.64m |
| pooling | 3.02k | 82.08k | 334.08k | 1.40m | 5.42m | 21.50m | 83.04m | ||
| Gift | 160 | fast | 17.92k | 200.48k | 516.32k | 1.24m | 6.45m | 13.10m | 42.24m |
| pooling | 17.92k | 244.32k | 714.88k | 2.21m | 8.51m | 29.12m | 102.40m | ||
| Gimli | 288 | fast | 2.69k | 84.96k | 342.72k | 1.19m | 4.57m | 17.09m | 67.20m |
| pooling | 2.69k | 190.56k | 832.80k | 3.52m | 14.06m | 56.16m | 218.88m | ||
| Ace | 384 | fast | 3.68k | 155.20k | 531.60k | 1.60m | 7.60m | 29.84m | 113.60m |
| pooling | 3.68k | 302.00k | 1.32m | 4.56m | 19.80m | 78.40m | 310.80m | ||
Since masking a multiplication has a quadratic cost in the number of shares, we expect performance at high orders to be mostly proportional with the number of multiplications used by the primitives. We thus report the number of multiplications involved in our implementations of the primitives. This is confirmed by our results with 128 shares (on the Cortex M4). This effect is less pronounced at small orders since the execution time remains dominated by linear operations. Using the pooling RNG increases the cost of multiplications compared to the fast RNG, which results in performances being proportional to the number of multiplications at smaller order than with the fast RNG.
Pyjamask illustrates the influence of the number of multiplications on scaling. Because of its use of dense binary matrix multiplications, it involves a significant number of linear operations for only a few multiplications. As a result, it is slower than Xoodoo at order 3, despite the fact that Xoodoo uses 2.5× more multiplications. With the fast RNG, the inflection point is reached at order 31 only to improve afterward. Similarly when compared to Clyde, Pyjamask goes from 5× slower at order 3 to 50% slower at order 127 with the fast RNG and 20% slower at order 127 with the pooling RNG. The same analysis applies to Gift and Gimli, where the linear overhead of Gift is only dominated at order 7 with the pooling RNG and at order 63 with the fast RNG.
One notable exception is Ascon with the fast RNG, compared in particular to Clyde and Pyjamask. Despite Ascon using only slightly more multiplications, it involves a 64-sliced implementation, unlike its counterparts that are 32-sliced. Running on our 32-bit Cortex-M4 requires GCC to generate 64-bit emulation code, which induces a significant operational overhead and prevents further optimization by the compiler. Regardless of the RNG used, Ascon is thus significantly slower than Clyde (at order 3 and beyond) and Pyjamask (at order 63 and beyond).
Bitslicing
The key limiting factor to execute bitslice code on an embedded device is the amount of memory available. Bitsliced programs tend to be large and to consume a significant amount of stack. Masking such implementations at high orders becomes quickly impractical because of the quadratic growth of the stack usage.
To reduce stack usage and allow us to explore high masking orders, our bitsliced programs manipulate 8-bit variables, meaning that 8 independent blocks can be processed in parallel. This trades memory usage for performance, as we could have used 32-bit variables and improved our throughput by a factor 4. However, doing so puts an unbearable amount of pressure on the stack, which would have prevented us from considering masking orders beyond 7. Besides, it is not clear whether there is a use-case for such a massively parallel (32 independent blocks) encryption primitive in a lightweight setting. As a result of our compilation strategy, we have been able to mask all primitives with up to 16 shares and, additionally, reach 32 shares for Photon, Skinny, Spongent and Subterranean.
| Bitslice performances (fast RNG) | ||||||
|---|---|---|---|---|---|---|
| primitive | mults/bits | Performances (cycles/bytes) (lower is better) |
||||
| d = 0 | d = 3 | d = 7 | d = 16 | d = 32 | ||
| Subterranean | 8 | 94 | 2.15k | 7.18k | 27.23k | 95.19k |
| Ascon | 12 | 101 | 3.07k | 11.45k | 42.39k | |
| Xoodoo | 12 | 112 | 3.12k | 10.49k | 38.35k | |
| Clyde | 12 | 177 | 3.44k | 13.57k | 45.34k | |
| Photon | 12 | 193 | 7.66k | 14.28k | 44.99k | 154k |
| Pyjamask | 14 | 1.59k | 16.52k | 31.76k | 97.88k | |
| Gimli | 24 | 127 | 5.51k | 19.15k | 76.91k | |
| Ace | 38 | 336 | 8.22k | 35.29k | 123k | |
| Gift | 40 | 358 | 11.08k | 36.79k | 136k | |
| Skinny | 48 | 441 | 18.19k | 61.75k | 200k | 664k |
| Spongent | 80 | 624 | 19.45k | 64.78k | 259k | 948k |
As for the n-sliced implementations, we observe a close match between the asymptotic performance of the primitive and their number of multiplications per bits, which becomes even more prevalent as order increases and the overhead of linear operations becomes comparatively smaller. Pyjamask remains a good example to illustrate this phenomenon, the inflection point being reached at order 15 with respect to Ace (which uses 3× more multiplications).
While Ascon with the fast RNG is slowed down by its suboptimal use of 64-bit registers in mslicing, its performance in bitslicing is similar to Xoodoo’s, which exhibits the same number of multiplication per bits.
| Bitslice performances (pooling RNG) | ||||||
|---|---|---|---|---|---|---|
| primitive | mults/bits | Performances (cycles/bytes) (lower is better) |
||||
| d = 0 | d = 3 | d = 7 | d = 16 | d = 32 | ||
| Subterranean | 8 | 94 | 4.46k | 19.13k | 79.63k | 312k |
| Ascon | 12 | 101 | 7.33k | 30.33k | 125k | |
| Xoodoo | 12 | 112 | 6.69k | 28.79K | 120K | |
| Clyde | 12 | 177 | 7.88k | 31.04k | 127k | |
| Photon | 12 | 193 | 10.47k | 31.77k | 126k | 476k |
| Pyjamask | 14 | 1.59k | 20.33k | 52.81k | 193k | |
| Gimli | 24 | 127 | 12.14k | 53.64k | 236k | |
| Ace | 38 | 336 | 19.94k | 89.12k | 395k | |
| Gift | 40 | 358 | 21.38k | 93.92k | 405k | |
| Skinny | 48 | 441 | 34.28k | 131k | 525k | 1.97m |
| Spongent | 80 | 624 | 44.04k | 188k | 816k | 3.15m |
Finally, we observe that with the pooling RNG, already at order 15, the performances of our implementations is in accord with their relative number of multiplications per bits. In bitslicing (more evidently than in n-slicing), the number of multiplications is performance critical, even at relatively low masking order.
Usuba vs reference and future work
Of these 11 NIST submissions, only Pyjamask provides a masked implementation. Our implementation is consistently (at every order, and with both the pooling and fast RNGs) 1.8 times slower than their masked implementation. The main reason is that they manually implemented in assembly the two most used routines.
The first one is a matrix multiplication. The Usuba code for this matrix multiplication is:
node mat_mult(col:u32,vec:u32) returns (res:u32)
vars
mask:u32
let
res = 0;
forall i in [0, 31] {
mask := bitmask(vec,i);
res := res ^ (mask & mat_col);
mat_col := mat_col[i] >>> 1;
}
tel
When compiled with gcc arm-none-eabi-gcc 4.9.3, the body of the loop compiles to 6 instructions. The reference implementation, on the other hand, inlines the loop and uses ARM’s barrel shifter. As a result, each iteration takes only 3 instructions. Using this hand-tuned matrix multiplication rather than Usuba’s matrix multiplication offers a speedup of 15% to 52%, depending on the masking order, as shown in the Table below:
| masking order | 3 | 7 | 15 | 31 | 63 | 127 |
|---|---|---|---|---|---|---|
| speedup | 52% | 49% | 43% | 34% | 24% | 15% |
The slowdown is less important at high masking orders because this matrix multiplication has a linear cost in the masking order, while the masked multiplication has a quadratic cost in the masking order (since it must compute all cross products between two shared values).
The second hand-optimized routine is the masked multiplication. The authors of the reference implementation used the same ISW multiplication gadget as we used in Usuba (shown in Section Masking), but manually optimized it in assembly. They unrolled twice the main loop of the multiplication, then fused the two resulting inner loops, and carefully assigned 6 variables to registers. If we note m the masking order, this optimization allows the masked multiplication to require m less jumps (m/2 for inner loops and m/2 outer loops), to use m/2 * 10 less memory accesses thanks to their manual assignment of array values to registers, and to require m/2*3 less memory accesses thanks to the merged inner loops. gcc fails to perform this optimization automatically.
Unlike the hand-optimized matrix multiplication, whose benefits diminish as the masking order increases, the optimized masked multiplication is more beneficial at higher masking order, as can be seen from the Table below, which compares it with the C implementation provied earlier in this post:
| masking order | 3 | 7 | 15 | 31 | 63 | 127 |
|---|---|---|---|---|---|---|
| speedup | 14% | 21% | 33% | 37% | 39% | 41% |
While the Usuba implementations can be sped up by using the hand-tuned version of the ISW masked multiplication, these two examples (matrix multiplication and masked multiplication) hints at the limits of achieving high performance by going through C. Indeed, while the superscalar nature of high-end CPUs can make up for occasional sub-optimal codes produced by C compilers, embedded devices are less forgiving. Similarly, Schwabe and Stoffelen [22] designed high-performance implementations of AES on Cortex-M3 and M4 microprocessors, and prefered to write their own register allocator and instruction scheduler (in less that 250 lines of Python), suggesting that gcc’s register allocator and instruction scheduler may be far from optimal for cryptography on embedded devices.
We leave for future work to directly target ARM assembly in Usuba, and to implement architecture-specific optimizations for embedded microprocessors. The resulting compiler backend is described in the figure below:
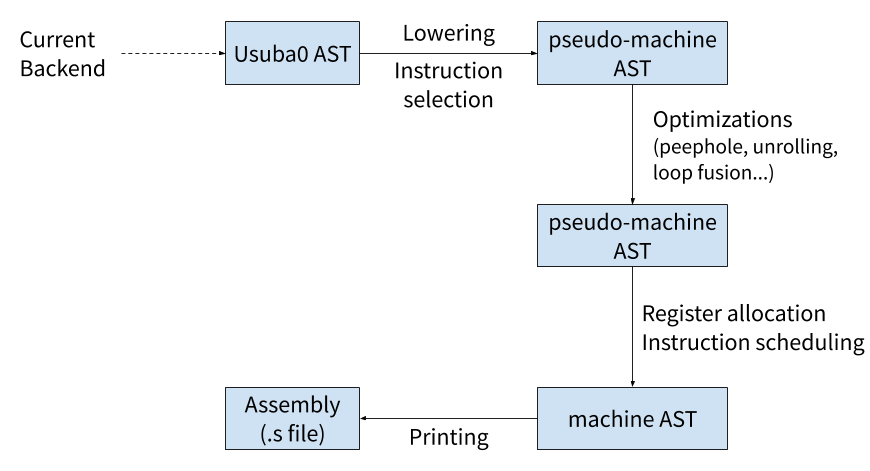
As of now, code-generation is the very last pass of Usubac, and does not go through its own intermediate representation (IR): the C code is generated directly from Usuba0. Optimizing down to assembly would require a “lowering” pass that would convert the Usuba0 into an assembly offering an infinite number of registers. Then, several optimization passes would be needed. Among the most important, a peephole optimizer would attempt to recognize and optimize commonly used idioms. For instance, a shift followed by an instruction using that shift could be optimized into a single instruction using the barrel shifter. Finally, register allocation and instruction scheduling (performed either separately or together) would produce an AST representing real machine code, which could then be printed to produce an assembly file. Each of those passes would be architecture-specific.
Related Work
Several approaches have been proposed to automatically secure implementations against power-based side-channel attacks. We review the main ones in chronological order.
Bayrak et al. [74] designed one of the first automated tool to protect cryptographic code at the software level. Their approach is purely empirical: they identify sensitive operations by running the cipher while recording power traces. The operations that are found to leak information are then protected using random precharging [73], which consists in adding random instructions before and after the offending instructions so as to lower the signal-to-noise ratio.
Agosta et al. [78] developed a tool to automatically protect ciphers against DPA using code morphing, which consists in dynamically (at runtime) generating and randomly choosing the code to be executed. To do so, the cipher is broken into fragments of a few instructions. For each fragment, several alternative (but semantically equivalent) sequences of instructions are generated at compile time. At runtime, a polymorphic engine selects one sequence from each of the fragments. The resulting code can leak secret data, but an attacker would not know where in the original cipher the leak is, since the code executing is dynamically randomized.
Moss et al. [76] proposed the first compiler to automate first-order
Boolean masking. Based on CAO [77], the developers annotates the
inputs of the program with secret or public, and the compiler
infers for each computation whether the result is secret (one of its
operand is secret) or public (all operands are public). The
compiler then searches for operations on secret values that break
the masking (for instance a xor where the masks of the operands
would cancel out), and fixes them by changing the masks of its
operands.
Agosta et al. [89] designed a dataflow analysis to automatically mask ciphers at higher orders. Their analysis tracks the secret dependencies (plaintext or key) of each intermediate variable, and is thus able to detect intermediate results that would leak secret information and require to be masked. They implemented their algorithm in LLVM [80], allowing them to mask ciphers written in C (although they require some annotations in the C code to identify the plaintext and key).
Sleuth [79] is a tool to automatically verify whether an implementation leaks information that is statistically dependent on any secret input and would thus be vulnerable to SCA. Sleuth reduces this verification to a Boolean satisfiability problem, which is solved using a SAT solver. Sleuth is implemented as a pass in the LLVM backend, and thus ensures that the compiler does not break masking by reordering instructions.
Eldib et al. [82] developed a tool similar to Sleuth called SC Sniffer. However, whereas Sleuth verifies that all leakage is statistically independent on any input, SC Sniffer ensures that a cipher is perfectly masked, which is a stronger property: a masked algorithm is perfectly masked at order d if the distribution of any d intermediate results is statistically independent of any secret input [27]. SC Sniffer is also implemented as a LLVM pass and relies on the Yices SMT solver [84] to conduct its analysis. Eldib and Wang [83] then built MC Masker, to perform synthesis of masking countermeasures (SC Sniffer only performs analysis). MC Masker generates the masked program using inductive synthesis: it iteratively adds countermeasures until the SMT solver is able to prove that the program is perfectly masked.
G. Barthe et al. [85] proposed to verify masking using program equivalence. More specifically, their tool (later dubbed maskverif), inspired by [86], tries to construct a bijection between the distribution of intermediate values of the masked program of interest and a distribution that is independent from the secret inputs. Maskverif scales better than previous work (eg. MC Masker) at higher masking order, even though it is not able to handle a full second-order masked AES. Furthermore, Maskverif works is not limited to analyze 1-bit variables, unlike Sleuth and SCSniffer.
G. Barthe et al. [87] later introduced the notion of strong non-interference. Intuitively, a strongly t-non-interfering code is t-probing secure (or t-non-interfering) and composable with any other strongly t-non-interfering code. This is a stronger property than t-probing security, since combining t-probing secure gadgets does not always produce a t-probing secure implementation [64]. They developed a tool (later dubbed maskComp) to generate masked C implementations from unmasked ones. Unlike previous work which could only verify the security of an implementation at a given order, maskComp is able to prove the security of an implementation at any order.
Coron [88] designed a tool called CheckMasks to automatically verify the security of higher-order masked implementations, similarly to maskverif [85]. For large implementations, CheckMasks can only verify the security at small orders. However, CheckMasks is also able to verify the t-SNI (or t-NI) property of gadgets at any order.
References
[1] Y. Ishai et al., Private Circuits: Securing Hardware against Probing Attacks, CRYPTO, 2003.
[2] K. Stoffelen, Efficient cryptography on the RISC-V architecture, LATINCRYPT, 2019.
[3] S. Belaïd et al., Tornado: Automatic Generation of Probing-Secure Masked Bitsliced Implementations, EUROCRYPT, 2020.
[4] M. Aagaard et al., ACE: An Authenticated Encryption and Hash Algorithm, 2019.
[5] C. Dobraunig et al., ASCON, 2019.
[6] D. Bellizia et al., Spook: Sponge-Based Leakage-Resilient Authenticated Encryption with a Masked Tweakable Block Cipher, 2019.
[7] S. Banik et al., GIFT-COFB, 2019.
[8] D. J. Bernstein et al., Gimli : A cross-platform permutation, CHES, 2017.
[9] Z. Bao et al., PHOTON-Beetle Authenticated Encryption and Hash Family, 2019.
[10] D. Goudarzi et al., Pyjamask, 2019.
[11] C. Beierle et al., SKINNY-AES and SKINNY-Hash, 2019.
[12] A. Bogdanov et al., SPONGENT: A lightweight hash function, CHES, 2011.
[13] T. Byene et al., Elephant v1, 2019.
[14] J. Daemen et al., The Subterranean 2.0 cipher suite, 2019.
[15] J. Daemen et al., Xoodoo cookbook, 2018.
[16] J. Daemen et al., Xoodyak, a lightweight cryptographic scheme, 2019.
[17] A. Chakraborti et al., Security Analysis of HYENA Authenticated Encryption Mode, 2019.
[18] S. Banik et al., SUNDAE-GIFT, 2019.
[19] T. Iwata et al., Romulus, 2019.
[20] B. Chakraborty, M. Nandi, ORANGE, 2019.
[21] A. Adomnicai et al., Fixslicing: A New GIFT Representation, TCHES, 2020.
[22] P. Schwabe, K. Stoffelen, All the AES You Need on Cortex-M3 and M4, SAC, 2016.
[23] P. Kocher et al., Differential Power Analysis, CRYPTO, 1999.
[24] G. R. Blakley, Safeguarding cryptographic keys, 1979.
[25] A. Shamir, How to Share a Secret, 1979.
[26] M. L. Akkar, C. Giraud, An Implementation of DES and AES, Secure against Some Attacks, CHES, 2001.
[27] J. Blömer et al., Provably Secure Masking of AES, SAC, 2004.
[28] T. S. Messerges, Securing the AES finalists against power analysis attacks, FSE, 2000.
[29] Y. Ishai et al., Private Circuits: Securing Hardware against Probing Attacks, CRYPTO, 2003.
[32] K. Tiri et al., A dynamic and differential CMOS logic with signal independent power consumption to withstand differential power analysis on smart cards, 2002.
[37] J. D. Golic, C. Tymen, Multiplicative Masking and Power Analysis of AES, CHES, 2002.
[38] S. Chari et al., Towards sound approaches to counteract power-analysis attacks, CRYPTO, 1999.
[39] L. Goubin, J. Patarin, DES and Differential Power Analysis, the duplication method, CHES, 1999.
[40] J. Daemen, V. Rijmen, Resistance Against Implementation Attacks A Comparative Study of the AES Proposals, 1999.
[41] T. Popp, S. Mangard, Masked dual-rail pre-charge logic: DPA-resistance without routing constraints, CHES, 2005.
[42] T. Messerges, Using second-order power analysis to attack DPA resistant software, CHES, 2000.
[45] J.-J. Quisquater, D. Samyde, ElectroMagnetic Analysis (EMA): Measures and CounterMeasures for Smart Cards, Esmart, 2002.
[46] K. Gandolfi et al., Electromagnetic Analysis: Concrete Results, CHES, 2001.
[47] J. R. Rao, P. Rohatgi, EMpowering Side-Channel Attacks, 2001.
[48] E. Biham, A. Shamir, Power Analysis of the Key Scheduling of the AES Candidates, 1999.
[49] P. C. Kocher, Timing Attacks on Implementations of Diffie-Hellman, RSA, DSS, and Other Systems, CRYPTO, 1996.
[50] W. Eck, Electromagnetic Radiation from Video Display Units: An Eavesdropping Risk, 1985
[51] P. Wright, Spycatcher – The Candid Autobiography of a Senior Intelligence Officer, 1987.
[52] J. Kesley et al., Side Channel Cryptanalysis of Product Ciphers, ESORICS, 1998.
[53] D. Page, Theoretical use of cache memory as a cryptanalytic side-channel, 2002.
[54] D. J. Bernstein, Cache-timing attacks on AES, 2005.
[55] J. Waddle, D. Wagner, Towards Efficient Second-Order Power Analysis, CHES, 2004.
[56] M. Joye et al., On Second-Order Differential Power Analysis, CHES, 2005.
[63] M. Rivain, E. Prouff, Provably Secure Higher-Order Masking of AES, CHES, 2010.
[64] J.-S. Coron et al., Higher-Order Side Channel Security and Mask Refreshing, FSE, 2013.
[65] K. Schramm, C. Paar, Higher Order Masking of the AES, CT-RSA, 2006.
[66] M. Rivain et al., Block Ciphers Implementations Provably Secure Against Second Order Side Channel Analysis, FSE, 2008.
[68] C. Carlet et al., Higher-Order Masking Schemes for S-Boxes, FSE, 2011.
[72] S. Belaïd et al., Tight Private Circuits: Achieving Probing Security with the Least Refreshing, ASIACRYPT, 2018.
[73] S. Tillich, J. Großschädl, Power Analysis Resistant AES Implementation with Instruction Set Extensions, CHES, 2007.
[74] A. G. Bayrak et al., A First Step Towards Automatic Application of Power Analysis Countermeasures, DAC, 2011.
[75] A. G. Bayrak et al., An Architecture-Independent Instruction Shuffler to Protect against Side-Channel Attacks, TACO, 2012.
[76] A. Miss et al., Compiler assisted masking, CHES, 2012.
[77] M. Barbosa et al., A domain-specific type system for cryptographic components, FSEN, 2011.
[78] G. Agosta et al., A Code Morphing Methodology to Automate Power Analysis Countermeasures, DAC, 2012.
[79] A. G. Bayrak et al., Sleuth: Automated verification of software power analysis countermeasures, CHES, 2013.
[80] C. Lattne, V. Adve, LLVM: A compilation framework for lifelong program analysis & transformation, CGO, 2004.
[81] C. Cada et al., KLEE: Unassisted and Automatic Generation of High-Coverage Tests for Complex Systems Programs, OSDI, 2008.
[82] H. Eldib et al., SMT-based verification of software countermeasures against side-channel attacks, TACAS, 2014.
[83] H. Eldib, C. Wang, Synthesis of Masking Countermeasures against Side Channel Attacks, CAV, 2014.
[84] B. Dutertre, L. De Moura, A fast linear-arithmetic solver for DPLL(T), CAV, 2006.
[85] G. Barthe et al., Verified Proofs of Higher-Order Masking, EUROCRYPT, 2015.
[86] G. Barthe et al., Formal Certification of Code-Based Cryptographic Proofs, POPL, 2009.
[87] G. Barthe et al., Strong Non-Interference and Type-Directed Higher-Order Masking, CCS, 2016.
[88] J.-S. Coron, Formal Verification of Side-channel Countermeasures via Elementary Circuit Transformations, ACNS, 2018.
[89] G. Agosta et al., Compiler-based Side Channel Vulnerability Analysisand Optimized Countermeasures Application, DAC, 2013.
[90] S. Belaïd et al., Tornado: Automatic Generation of Probing-Secure MaskedBitsliced Implementations, EUROCRYPT, 2020.
[91] J.S. Coron et al., Side Channel Cryptanalysis of a Higher Order Masking Scheme, CHES, 2007.
[92] A. Battistello et al., Horizontal side-channel attacks and countermeasures on the ISW masking scheme, CHES, 2016.